AMDGPU 寄存器初始化与ELF文件分析
1. 引言
在kernel函数的prologue中,有一些初始化代码。它们直接从特定的scalar寄存器中实施访存,那么这些scalar寄存器表示什么含义?又是由谁进行设置的呢?解答这些问题的关键在于AMDGPU的ELF文件。
2. kernel launch的过程概述
在进一步探讨问题之前,我们先来回顾一个kernel从host launch再到硬件执行的基本过程。了解编译器、runtime以及硬件各自的分工。需说明的是这里只做概述,更详细准确的内容请RTFM & RTFSC。
- clang在实施hip文件的host端编译时,会识别«<»>的语法,然后生成device_stub并调用该stub函数。
- device_stub调用hipLaunchKernel这一clr runtime API。
- HIP runtime 创建一个kernel 启动命令,并放入runtime管理的队列中。
- runtime随后将“启动命令”转化为AQL数据包,将其放入HSA 队列中。过程如下:
- 首先获取AQL队列的指针,以便后续存放AQL数据包(也就是kernel dispatch packet)。
- 之后获取kernel 描述符(kernel descriptor)的指针。
- 接着在GPU constant memory中分配空间存放kernel的参数,并将参数拷贝至该空间中。
- 再然后runtime创建一个AQL数据包并原子地放到HSA 队列中。AQL设计了一种门铃机制用于通知GPU HSA队列被更新了(貌似是通过IOMMU的方式),AMDGPU的CP(Command Processor)将处理HSA队列中的请求。
- CP中的ACE(异步计算引擎)将处理HSA队列中的请求,分配到合适的SE并分配硬件资源。
- CP将执行微码来初始化wavefronts的执行环境。以确保scalar/vector寄存器中的值符合kernel运行的初始状态,这些初始状态则是由4.b中的内核描述符确定。之后硬件就能正确执行kernel代码了。
以上就是kernel launch的基本过程了。该过程中所提及的HSA,全称是Heterogeneous System Architecture,是AMD、ARM等设计的一套异构系统的标准,AMDGPU遵循了该标准的一些设计。在该标准中AQL kernel dispatch数据包的格式如下:
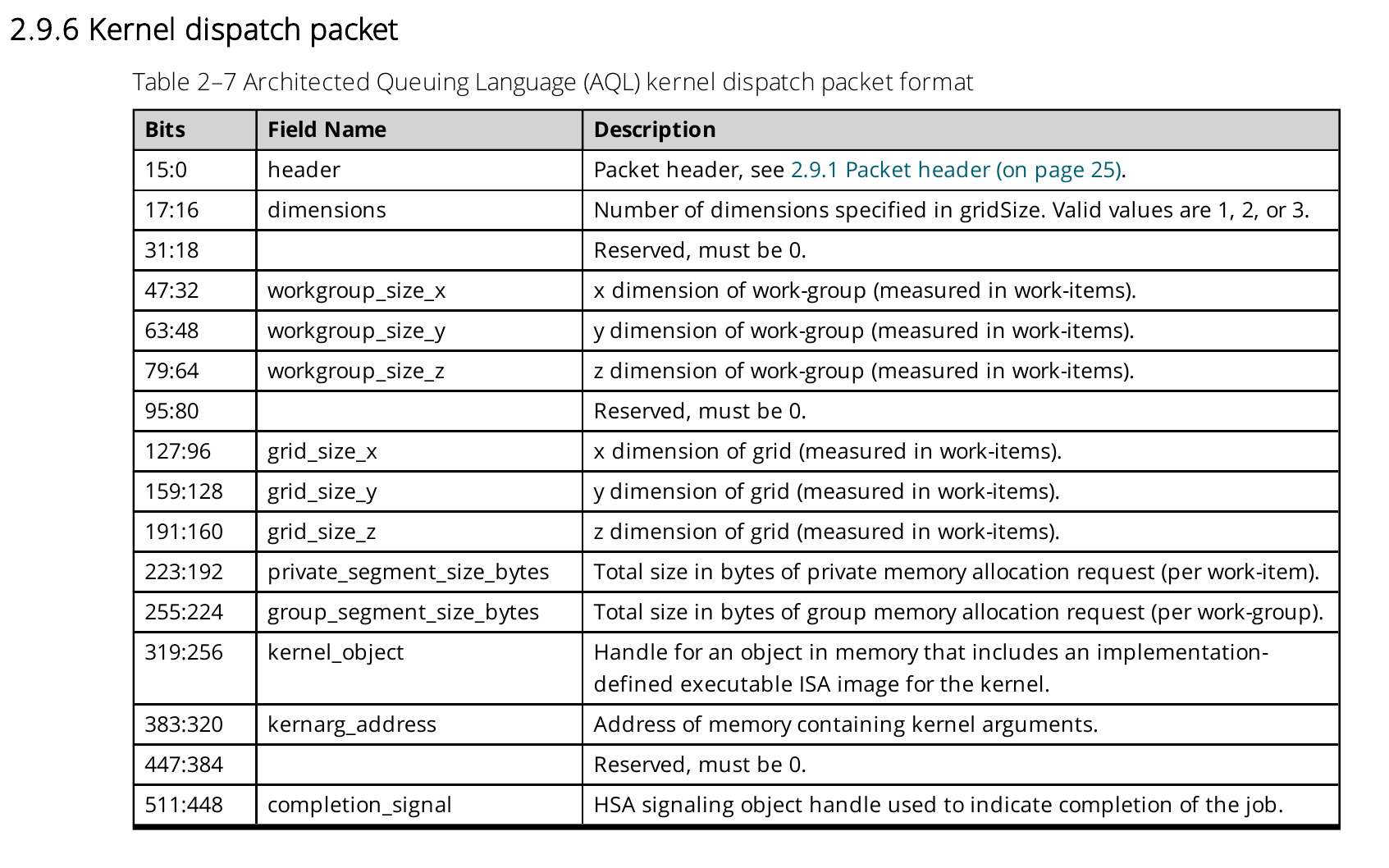
其中包含诸如blockDim、gridDim的相关信息。比如我们在kernel中需要使用blockDim.x时,实际就会访问该packet中的workgroup_size_x成员:

该例子中的llvm.amdgcn.dispatch.ptr就是指向一个AQL kernel dispatch packet的指针,访问的第4字节刚好就是workgroup_size_x,也就是blockDim.x。
另外在LLVM AMDGPU的文档中也叙述了kernel launch的这一过程,这里贴上其陈述,作为参考:

3. kernel descriptor初探
3.1 什么是kernel descriptor?
A kernel descriptor consists of the information needed by CP to initiate the execution of a kernel, including the entry point address of the machine code that implements the kernel. – AMDGPU文档
内核描述符中记录了CP初始化内核执行环境所需要的信息。比如内核参数大小、内核代码的位置、wavefront size是32还是64、是否开启了某些特殊功能等。根据信息的不同,CP会给不同scalar/vector寄存器放入不同的值。AMDGPU规定内核描述符需要按照64字节对齐,并且大小也为64字节。
3.2 kernel descriptor在ELF中的位置
内核描述符最开始由编译器产生,保存在ELF中,之后HIP runtime会解析fatbin中的ELF并将其下发给GPU。之后CP将根据内核描述符的规定初始化寄存器。
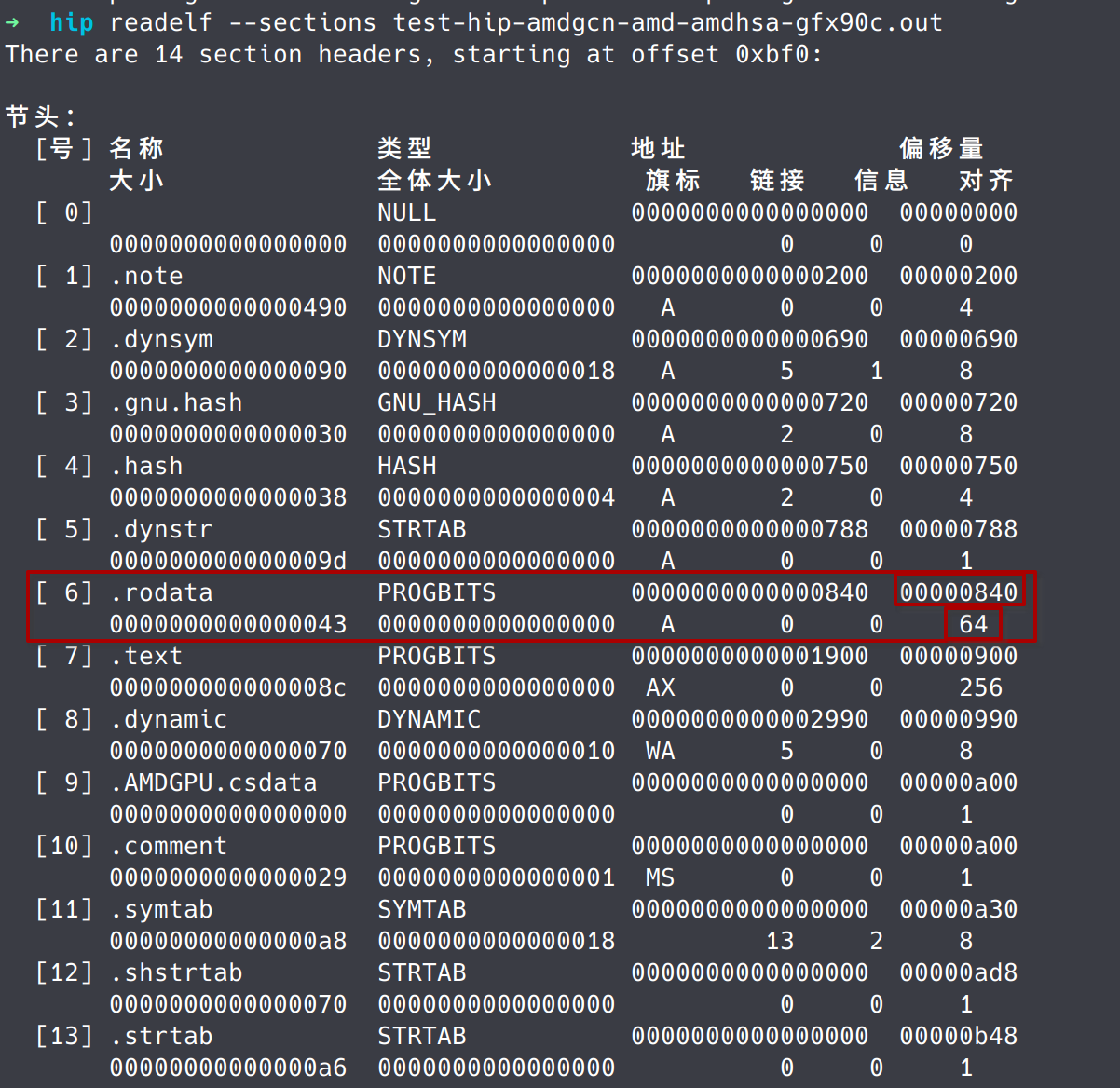
ELF中该内核描述符的位置由符号link-name.kd确定,且位于.rodata section中:
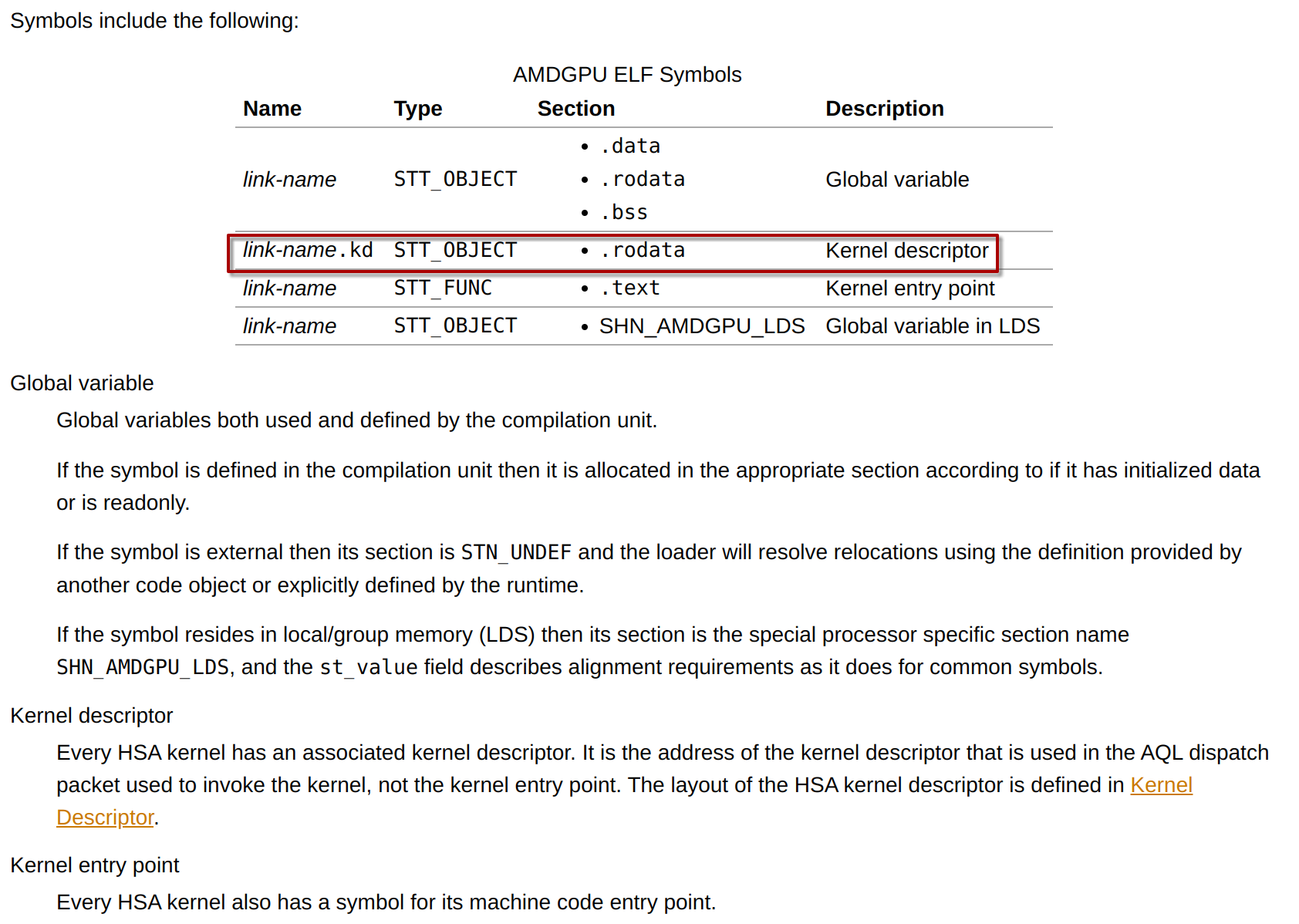
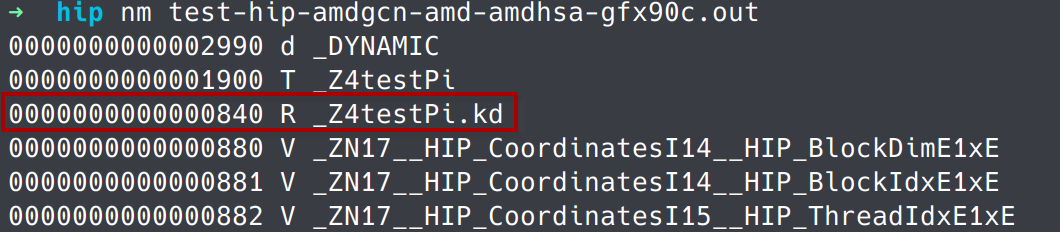
可以直接使用nm查看该符号以及值,并在.rodata section中找到其位置:
3.3 内核描述符格式
可以在llvm-project/llvm/include/llvm/Support/AMDHSAKernelDescriptor.h中找到描述符的结构体定义:
// Kernel descriptor. Must be kept backwards compatible.
struct kernel_descriptor_t {
uint32_t group_segment_fixed_size; // kernel所使用的share memory 大小
uint32_t private_segment_fixed_size; // kernel所使用的private/scratch memory 大小
uint32_t kernarg_size; // kernel 参数大小
uint8_t reserved0[4];
int64_t kernel_code_entry_byte_offset; // 内存中代码段相对该描述符的偏移。描述符地址+offset == .text代码段地址
uint8_t reserved1[20];
uint32_t compute_pgm_rsrc3; // GFX10+ and GFX90A+
uint32_t compute_pgm_rsrc1;
uint32_t compute_pgm_rsrc2;
uint16_t kernel_code_properties; // 一些标志,表明是否开启某些功能
uint8_t reserved2[6];
};
有关描述符各字段的含义,可以参考LLVM官方文档的说明。这里做一些简要说明:
- group_segment_fixed_size是指kernel使用的share memory大小,一般是__shared__修饰的变量。
- private_segment_fixed_size是使用到的scratch memory大小,一般是局部变量在register spill时分配的变量大小。
- kernarg_size是runtime在constant memory上分配的用于存储内核参数的内存大小。
- kernel_code_entry_byte_offset是指ELF中各段被加载到constant memory后,代码段(.text)相对描述符所在地址(.rodata)的偏移。
下面我们实际查看下ELF中内核描述符的内容:
- 首先我们将如下kernel进行编译,编译时加入–save-temps得到device侧ELF文件,该文件一般以.out结尾:
__global__ void test(int *a) {
__shared__ int x[10]; // 40字节的share memory
if (blockDim.x == 2 && gridDim.x == 1) {
for (int i = 0; i < 10; i++)
x[i] = a[i];
for (int i = 0; i < 10; i++)
x[0] += x[i];
}
a[0] = x[0];
}
- 之后使用objdump -s -j .rodata test-hip-amdgcn-amd-amdhsa-gfx90c.out 得到内核描述符的二进制内容:
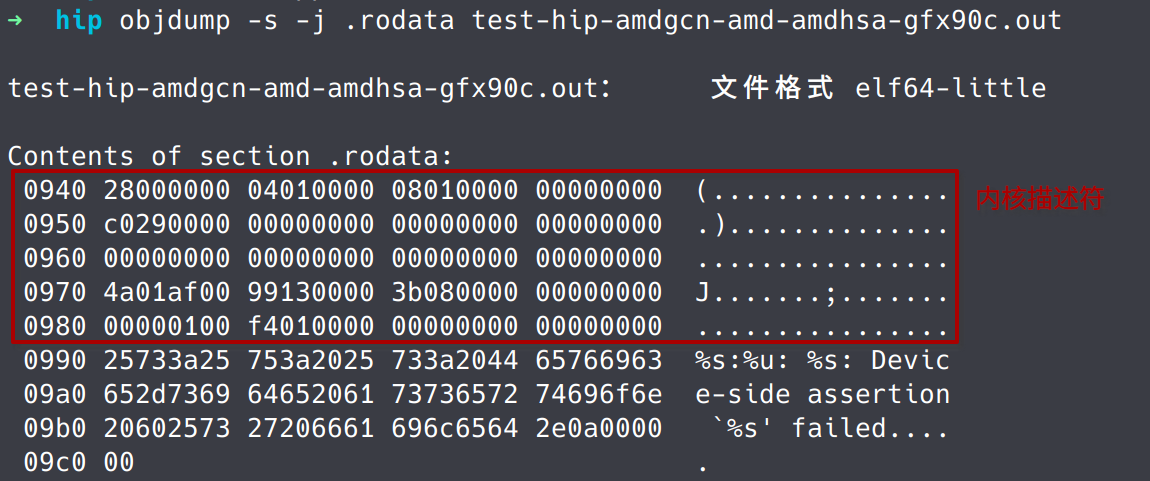
可以看到描述符的前4字节是0x28,刚好是40字节,与我们声明的share memory大小一致。其余字段大家感兴趣可自行分析。
.note section的元数据信息
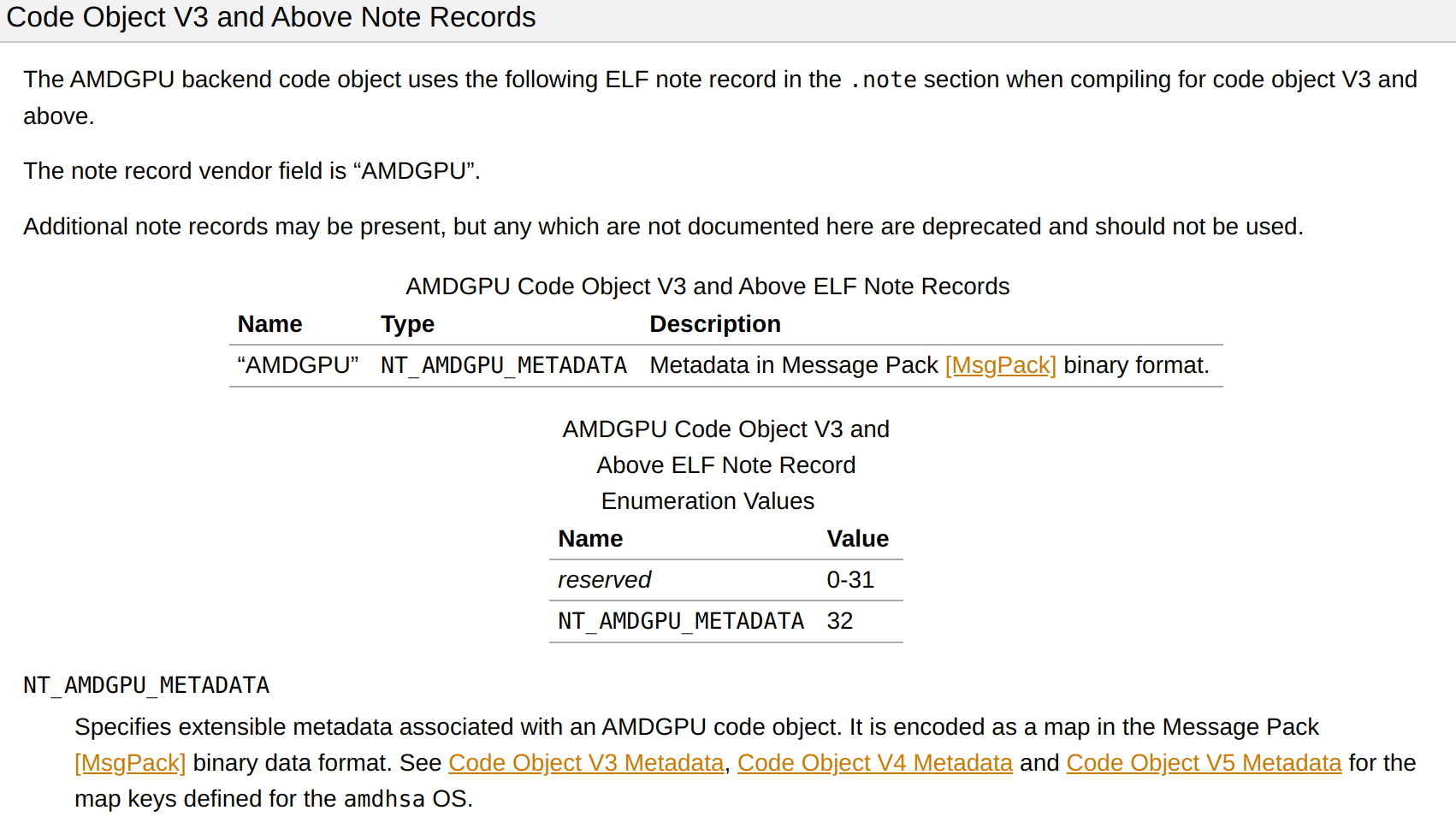
除了位于.rodata section的内核描述符,AMDGPU ELF在.note section也携带了内核参数、group_segment_fixed_size等诸多信息。该section是以message pack二进制格式表示的元数据信息。LLVM文档中有其说明:
为了一探究竟,可以使用readelf -n test-hip-amdgcn-amd-amdhsa-gfx90c.out来输出.note section的数据:
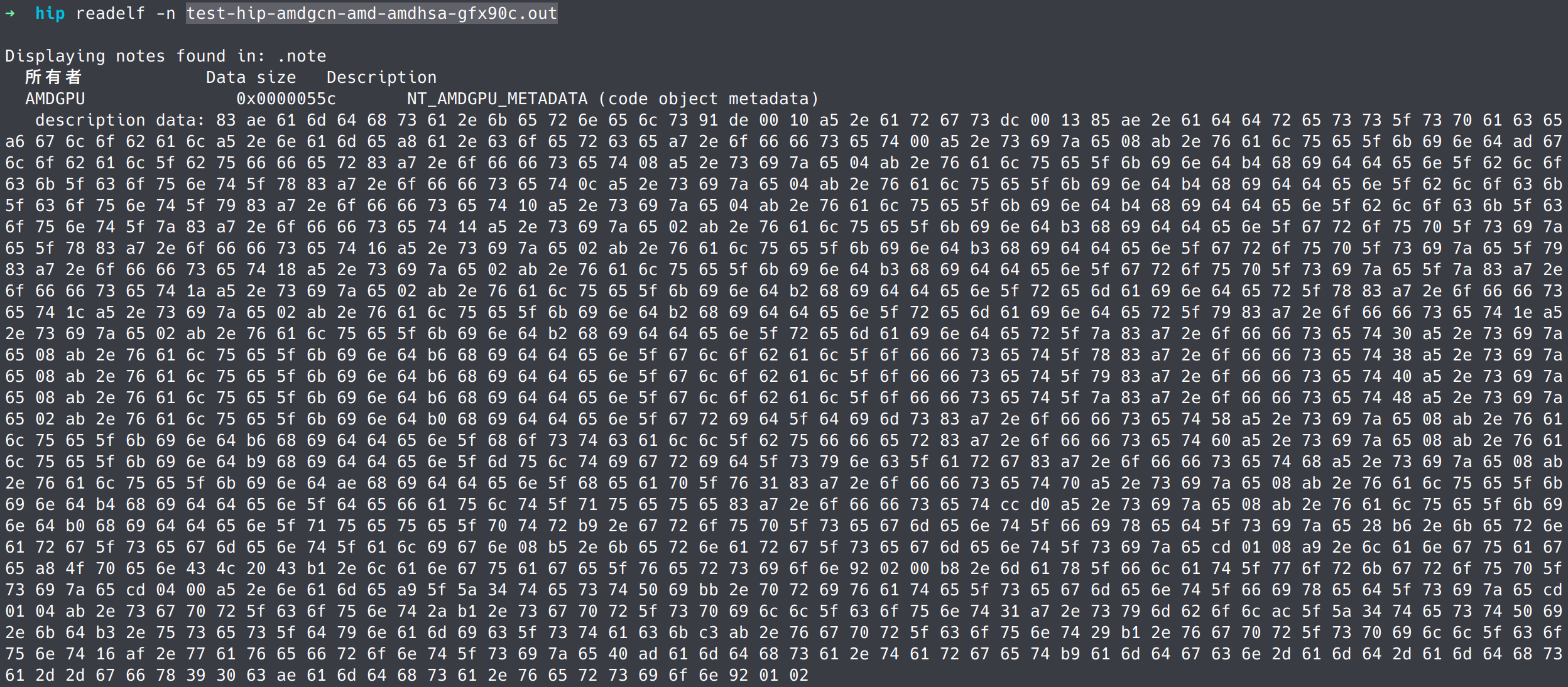
由于数据是二进制格式,我们可以通过一些在线的message pack转换工具,将其转成json文件。此例中转换后的json如下:
{
"amdhsa.kernels": [
{
".args": [
{
".address_space": "global",
".name": "a.coerce",
".offset": 0,
".size": 8,
".value_kind": "global_buffer"
},
{
".offset": 8,
".size": 4,
".value_kind": "hidden_block_count_x"
},
{
".offset": 12,
".size": 4,
".value_kind": "hidden_block_count_y"
},
{
".offset": 16,
".size": 4,
".value_kind": "hidden_block_count_z"
},
{
".offset": 20,
".size": 2,
".value_kind": "hidden_group_size_x"
},
{
".offset": 22,
".size": 2,
".value_kind": "hidden_group_size_y"
},
{
".offset": 24,
".size": 2,
".value_kind": "hidden_group_size_z"
},
{
".offset": 26,
".size": 2,
".value_kind": "hidden_remainder_x"
},
{
".offset": 28,
".size": 2,
".value_kind": "hidden_remainder_y"
},
{
".offset": 30,
".size": 2,
".value_kind": "hidden_remainder_z"
},
{
".offset": 48,
".size": 8,
".value_kind": "hidden_global_offset_x"
},
{
".offset": 56,
".size": 8,
".value_kind": "hidden_global_offset_y"
},
{
".offset": 64,
".size": 8,
".value_kind": "hidden_global_offset_z"
},
{
".offset": 72,
".size": 2,
".value_kind": "hidden_grid_dims"
},
{
".offset": 88,
".size": 8,
".value_kind": "hidden_hostcall_buffer"
},
{
".offset": 96,
".size": 8,
".value_kind": "hidden_multigrid_sync_arg"
},
{
".offset": 104,
".size": 8,
".value_kind": "hidden_heap_v1"
},
{
".offset": 112,
".size": 8,
".value_kind": "hidden_default_queue"
},
{
".offset": 208,
".size": 8,
".value_kind": "hidden_queue_ptr"
}
],
".group_segment_fixed_size": 40,
".kernarg_segment_align": 8,
".kernarg_segment_size": 264,
".language": "OpenCL C",
".language_version": [
2,
0
],
".max_flat_workgroup_size": 1024,
".name": "_Z4testPi",
".private_segment_fixed_size": 260,
".sgpr_count": 42,
".sgpr_spill_count": 49,
".symbol": "_Z4testPi.kd",
".uses_dynamic_stack": true,
".vgpr_count": 41,
".vgpr_spill_count": 22,
".wavefront_size": 64
}
],
"amdhsa.target": "amdgcn-amd-amdhsa--gfx90c",
"amdhsa.version": [
1,
2
]
}
寄存器初始化
如前所述,GPU在执行kernel之前会由CP初始化一些寄存器状态。CP会按照预先定义的顺序,遍历一些状态信息,如果该状态信息在kernel descriptor中是开启的(标志位是1),则将该状态依次赋值到从0开始的scalar或者vector寄存器。
以scalar寄存器(SGPRS)为例,LLVM官方文档的说法如下:
The order of the SGPR registers is defined, but the compiler can specify which ones are actually setup in the kernel descriptor using the
enable_sgpr_*bit fields (see Kernel Descriptor). The register numbers used for enabled registers are dense starting at SGPR0: the first enabled register is SGPR0, the next enabled register is SGPR1 etc.; disabled registers do not have an SGPR number.
按照文档描述,CP需要遍历下图中的第二列状态信息:
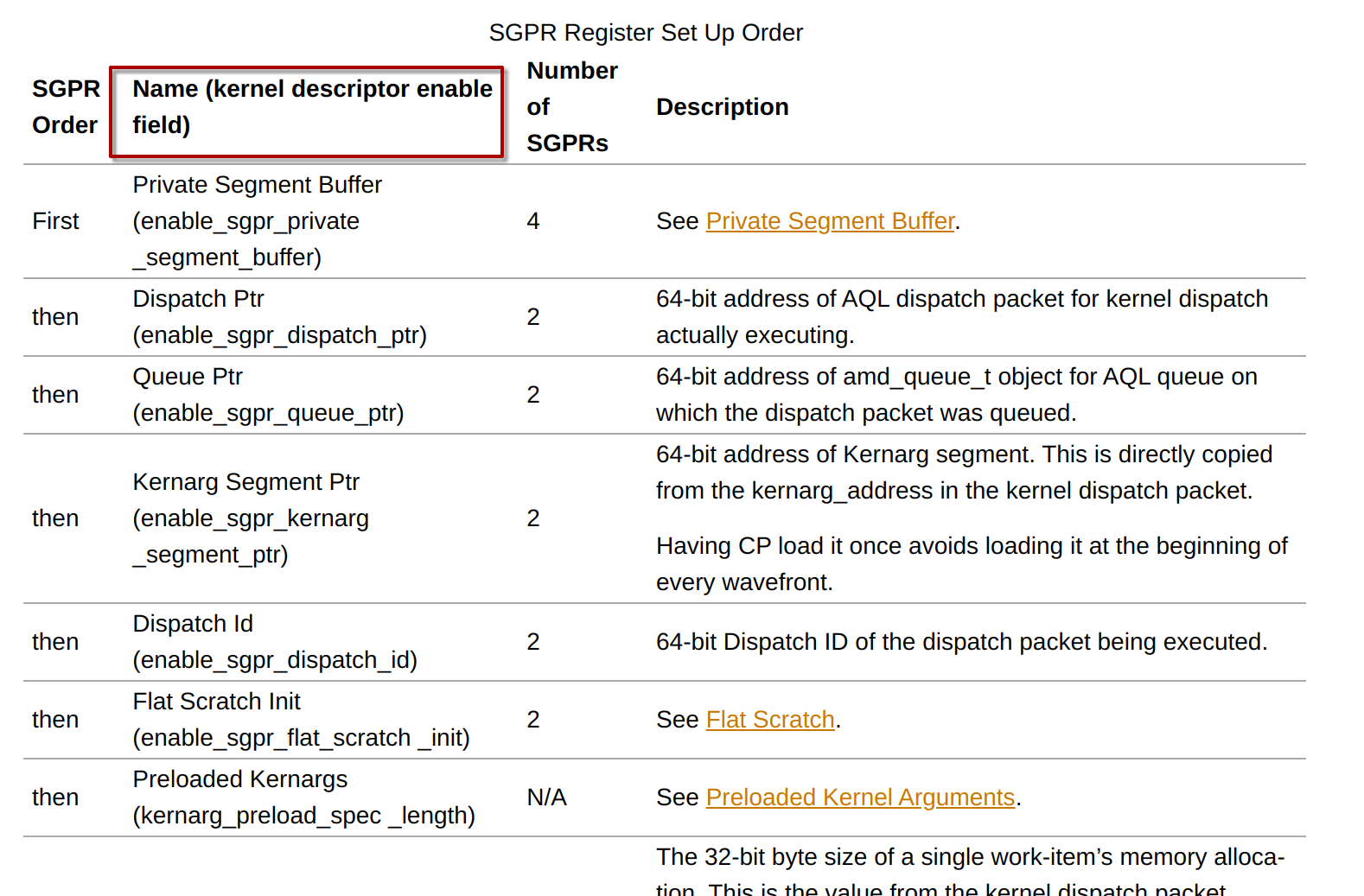
如果内核描述符中enable_sgrp_private_segment_buffer为1,则s[0-3]初始化为private segment buffer;接着,如果enable_sgpr_dispatch_ptr是1,则s[4-5]被CP初始化为AQL kernel dispatch packet的地址(这也就是本文引言中寄存器的含义)。否则,s[4-5]保存后续遍历中使能的状态信息,这里就不再赘述了。
vector寄存器的初始化类似,具体请参考文档。