AMDGPU 访存系统之指令概述(其一)
1. 引言
随着处理器算力的快速发展,存储器的带宽提升速度已经大幅落后于处理器, 大部分冯诺依曼架构的计算系统都已面临严重的存储墙问题。针对这一问题,体系结构的研究人员从包括近存计算、存内计算、复杂cache机制等多个方面对硬件架构进行设计,试图缓解这一瓶颈问题。但这也导致了愈发复杂的访存指令系统。
本文将梳理AMDGPU的访存系统,并对其指令类别与寻址方式进行分析。本文中所参考的资料主要包括CDNA架构的白皮书、CDNA指令集以及LLVM官方文档。受限于个人理解的局限性(智商不足)以及官方文档的准确性(垃圾文档),部分分析可能存在不足与疏漏,欢迎大家讨论与修正(免责声明)。
2. 硬件存储层次
在传统CPU中,cache对指令透明,不占用地址空间,也不可寻址,所起的作用是作为内存的副本从而加速访问。然而,GPU为了保证线程之间频繁的数据交互与共享,不仅拥有大量的片外(off-chip)显存,还设计一套片上存储。这些片上存储具有独立的地址空间,可使用特定的指令与寻址方式进行访问。这种方式可以让用户手动管理高速的片上存储,提供相较硬件管理更加高效的资源利用率。
2.1 AMDGPU CDNA基本架构
在讲解AMDGPU存储层次前,有必要先了解下AMDGPU的整体架构,明白存储系统在架构中的位置。
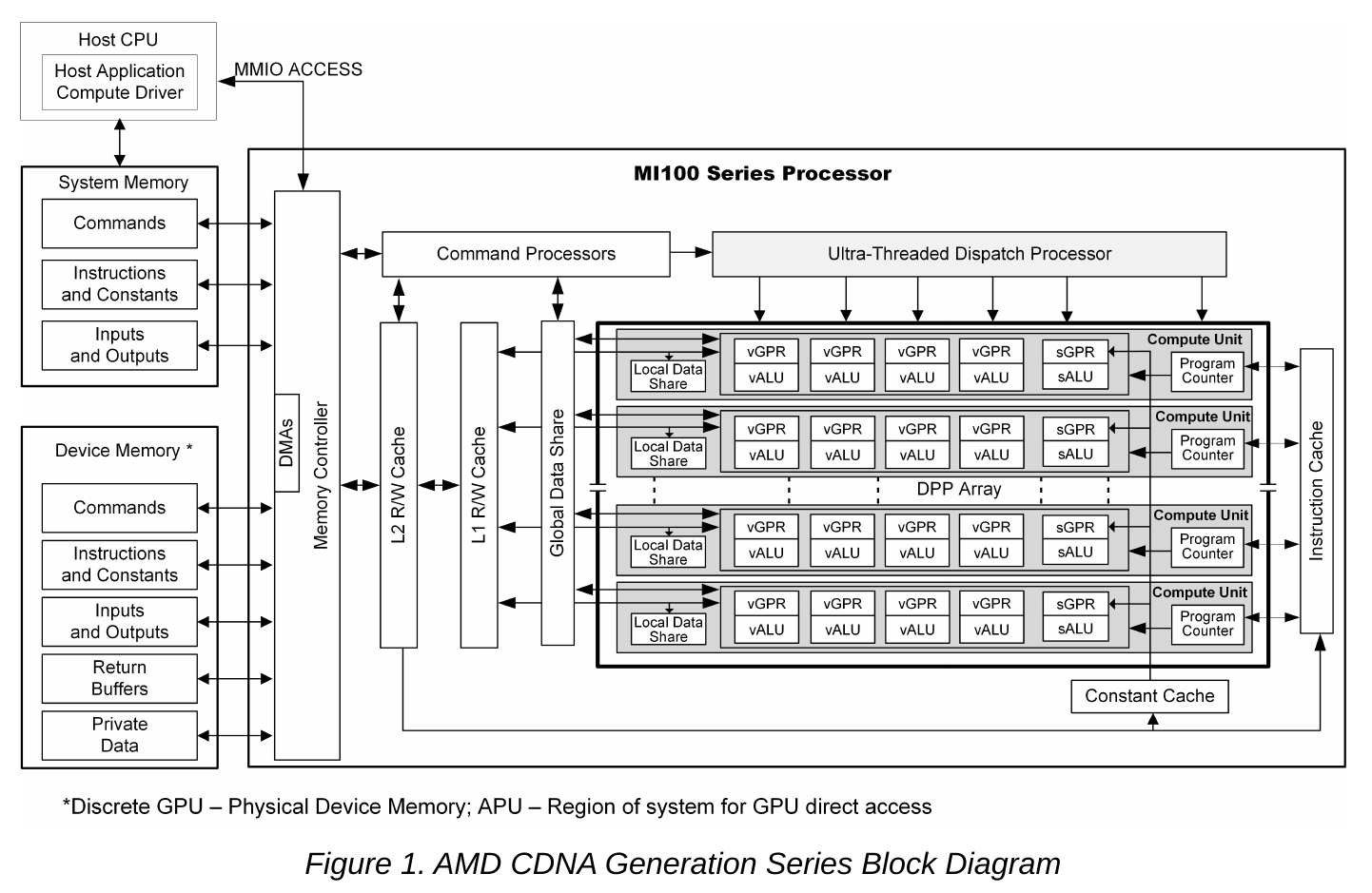
- 一个kernel程序的执行环境包括宿主机CPU与设备端GPU。CPU通过MMIO的方式读写GPU的端口寄存器,控制主机内存与设备内存之间的传输、以及kernel的启动。
- 设备端GPU由内存控制器、Command Processor(简称CP)、计算单元(简称CU)、cache、片上存储以及其他控制逻辑组成。
- 内存控制器负责访问主机内存与设备内存,并能实现两者之间的DMA。
- CP负责接收主机的各类命令,创建kernel的执行环境以及分配所需硬件资源等。CP也负责对kernel进行调度,并能向宿主机CPU发送中断。
- CU负责各类运算,包含多个向量运算单元vALU与标量运算单元sALU,是算力核心。
- 片上存储模块实现数据共享与高速访问,包括LDS(Local Data Share)、GDS(Global Data Share)。
- cache模块缓存设备内存,与CPU cache作用一致。包括指令cache、常量cache(有时也称为scalar cache),以及L1,L2 cache。
2.2 存储层次
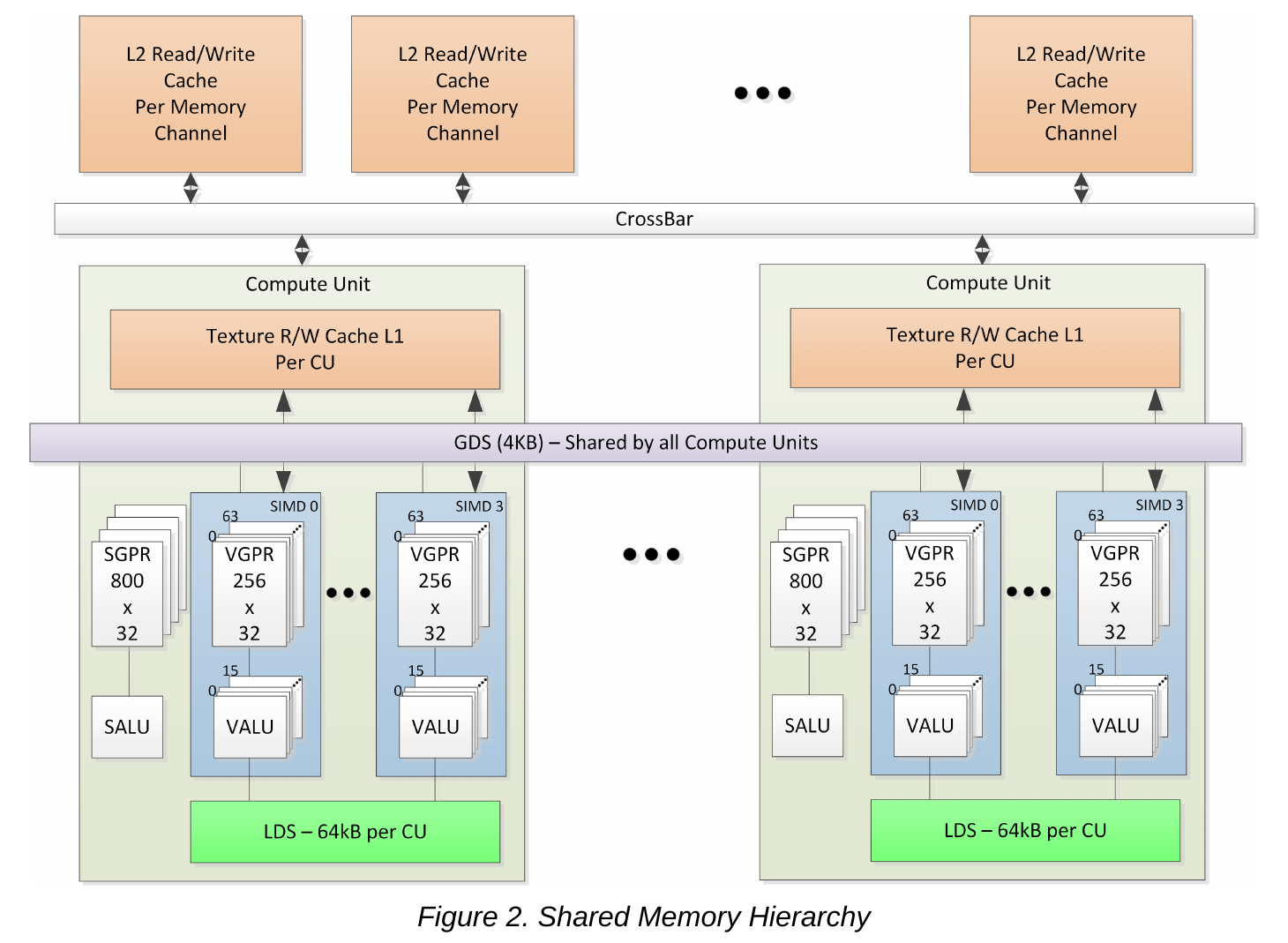
- Device Momory是位于片外的显存。其容量最大(CDNA架构中约32GB),但访问延迟也最高。我们软件上常说的global memory就是指该存储区域。另外constant memory与scratch/private memory也位于device memory中,如图1中的“Instructions and Constant”、”private data”。该内存具有编址空间。
- 为了加速device memory的访问,CDNA使用了L1, L2,constant cache缓存device memory的数据。其中,L2 cache是CDNA的last level cache,由整个设备共享。L1 cache是per-CU的私有cache,速度相较L2更快。constant cache则是缓存constant memory的cache,由SMEM指令操作,也称为scalar cache。
- LDS/GDS可用作不同线程之间共享数据的存储区域。两者都是片上存储,具有较高的访问速度。其中LDS是per-CU的,可用作CU内线程之间的数据共享。由于硬件保证一个block会调度到一个CU中,因此LDS可供block内所有线程共同访问。GDS由所有CU共享,可供同一设备内所有线程访问,可用于保存一些控制数据。另外GDS没有HIP源代码层面对应的使用语法,如需使用,需以汇编的形式手动调用相关指令。与device momory一样,LDS/GDS具有编址空间。
3. 地址空间
前面已经从硬件的角度介绍了GPU的存储层次,本节从软件的角度介绍如何访问这些内存区域(地址空间)。
AMDGPU 已经实现的地址空间有如下几种:
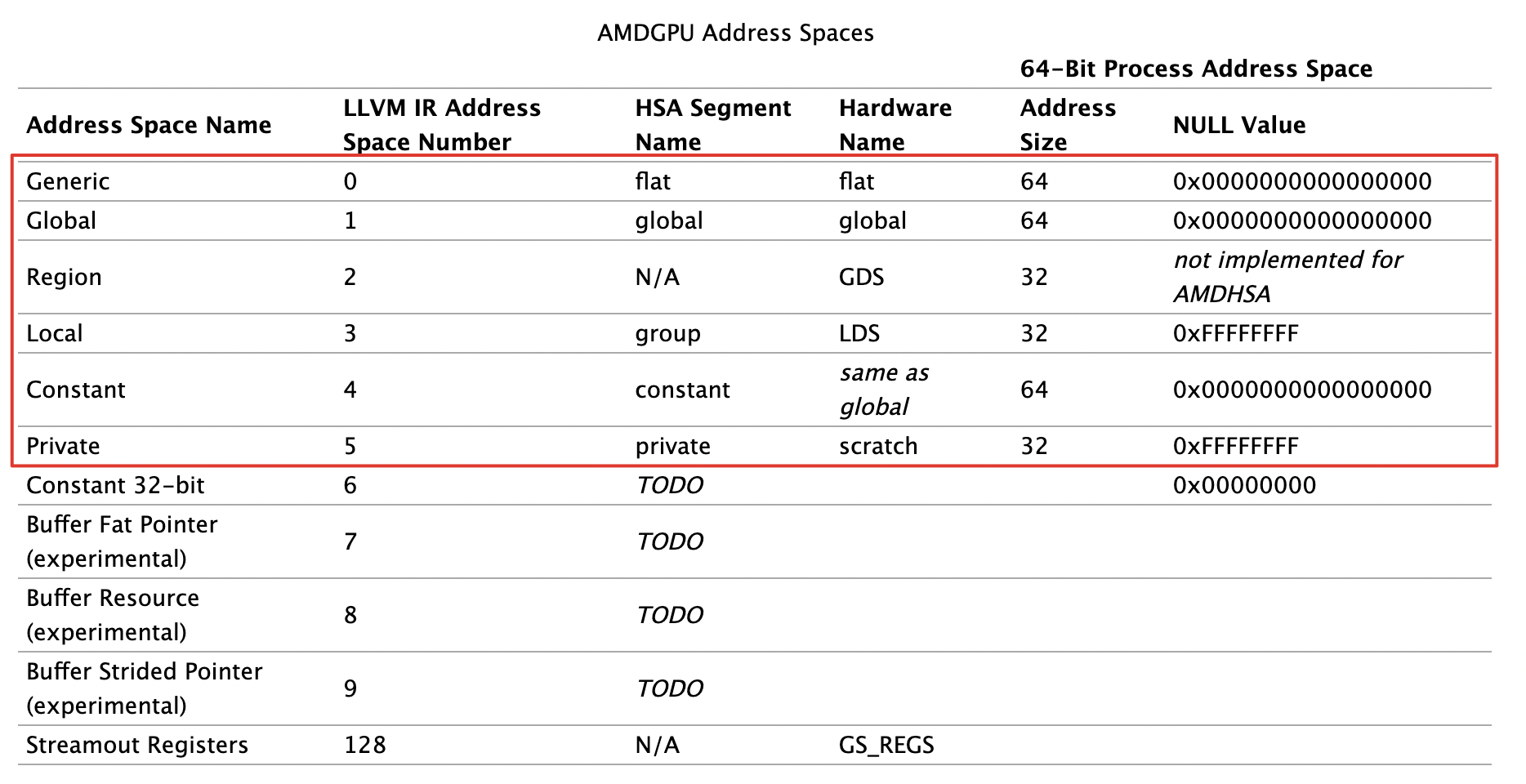
3.1 Generic 空间
该空间使用硬件的flat地址去访问global、private(scratch)以及group(LDS)内存区域。generic给这三种内存区域提供了统一的编址,因此当编译器不确定某指针所指向的内存区域时,就可以使用flat指令实施访存。但是代价是效率可能不如具体内存的访存指令,因为硬件首先需要判断该地址落在那个内存窗口(memory aperture)。下面将介绍下不同地址空间的窗口以及访问方式。
不同的内存区域(LDS, private等)在AMD的代码或者文档中也称为一个段(segment)。每个段有自己的base与limit,分别对应基地址与尾地址(有时也用大小表示)。这种分段模式与CPU的分段其实没有本质区别,X86 CPU中也有代码段、数据段、内核段,通过GDT来获取相应段描述符,从而得到base与limit。与CPU不同,AMDGPU记录LDS, private所在段的base,limit位于特殊的硬件寄存器中,分别是src_shared_base/limit与src_private_base/limit。某个变量位于段内的偏移加上段基址就得到了线性地址,或者说flat地址了。
现在来具体感受下src_shared_base/limit与src_private_base/limit,我们用如下的内核代码进行实验:
__global__ void test() {
long long private_base;
long long private_size;
long long share_base;
long long share_size;
long long scratch;
asm volatile("s_mov_b64 %0, src_private_base" : "=rr"(private_base));
asm volatile("s_mov_b64 %0, src_private_limit" : "=rr"(private_size));
asm volatile("s_mov_b64 %0, src_shared_base" : "=rr"(share_base));
asm volatile("s_mov_b64 %0, src_shared_limit" : "=rr"(share_size));
asm volatile("s_mov_b64 %0, flat_scratch" : "=rr"(scratch));
if (threadIdx.x == 0) {
printf("private base 0x%llx limit 0x%llx\nshare base 0x%llx limit 0x%llx\nprivate_var addr %p\nglobal_var addr %p\nflat_scratch_reg 0x%llx\n", private_base, private_size, share_base, share_size, &private_base, in, scratch);
}
}
得到如下输出:
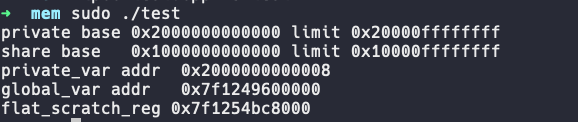
可以看到private的aperture为[0x2000000000000, 0x20000ffffffff]。share的aperture为[0x1000000000000, 0x10000ffffffff]。这两个区域大小都为2^32=4G字节,地址空间都超出了global的48位地址空间范围,因此不会重叠。
另外我们定义的一个局部变量地址为0x2000000000008,恰好落在private的aperture内,符合预期。事实上,编译器内的两个builtin __builtin_amdgcn_is_shared与__builtin_amdgcn_is_private的实现就是判断地址的高32位是否与src_shared_base,src_private_base相同。
我们现在看到的打印地址都是flat地址,这也是暴露给程序员的顶层虚拟地址,之所以说是顶层虚拟地址,是因为flat地址可能还会转换成其他虚拟地址,再最终转成物理地址。这种地址转换逻辑大致如下图:
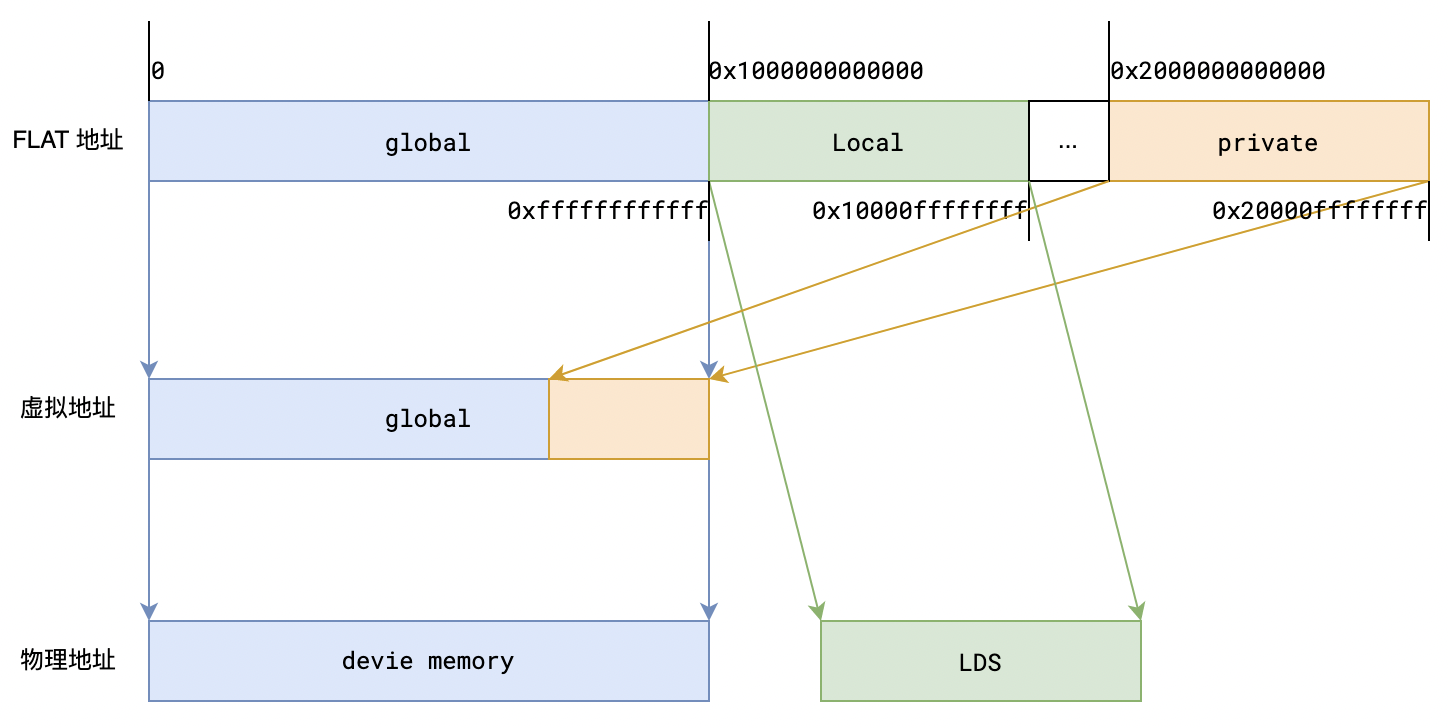
访问global区间的flat地址可直接用其访问物理地址(可能经过MMU的VA->PA的转换)。表示Local区间的flat地址也可直接访问LDS上的物理地址(硬件自动转换,用户无需关心)。但是表示private区间的flat地址逻辑上可认为需要先转成global虚拟地址,然后再访问物理地址(global地址再通过MMU的VA->PA转换)。private特殊在其是线程私有的,不同线程同一个private地址会被映射为不同的global地址,该块global区域也被称为private segment buffer,并且是swizzled buffer。现在来解释下swizzle的含义以及private地址的映射过程。
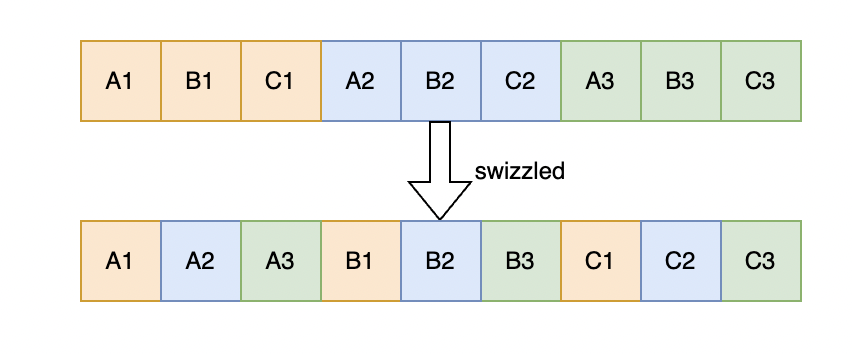
假设有3个线程,每个线程有A,B,C三个变量,并且三个变量在普通情形下会被放到一起。由于GPU按照wavefronts运行,一般会同时访问各自的变量,比如都访问A,那么普通的layout会导致线程之间访问不连续(如下图中的A1,A2,A3),破坏L1,L2 cache局部性。于是,GPU采用了一种swizzled的布局,即将每个线程的第一个element放到一起,然后将下一个element放到一起,重复该操作直至所有element都被重新排放!采用swizzle布局的访存速度就能大幅提高。在AMDGPU中element size固定为4字节。
那么给定一个位于private区间的flat地址,如何得到转换后的global地址呢?假设一个位于private区间的flat地址X,并且设private的基地址为private.base,计算过程如下:
- 首先得到本wavefront在private_segment_buf中的起始地址。计算方式是:
其中wave.id是与warp id类似,wavefront_size是wave的线程数,CDNA中默认是64,scratch_size是kernel中一个线程所需scratch memory的大小,可在ELF的内核描述符中找到。
- 接着计算该wave内,地址X所属element之前的element所占用的大小。比如图6中,如果X位于C2中,那么计算的就是所有线程A,B所占大小,也就是A1,A2,A3,B1,B2,B3的大小。计算方式是:
- 然后计算wave中,与X所属同一element,但wave id更小的element大小。比如图6中,如果X位于C3,那么计算的就是C1+C2的大小:
- 最后,计算X在element中的偏移,比如图6中,如果X位于C3,那么就是X在C3中的偏移:
最终将(1),(2),(3),(4)相加即得到最终的global地址:
\[private\_segment\_buf.base + wave.id * wavefront\_size * scratch\_size +\] \[((X-private.base) / element\_size)*element\_size * wavefront\_size +\] \[wave.id * element\_size + (X-private.base) \% element\_size\]在AMDGPU中,(1)的计算结果位于flat_scratch寄存器,GPU的CP将加法的左右两边分别放入了sgpr寄存器,然后在kernel的prolog中将两者相加存入flat_scratch。这部分可以参考这篇文章的寄存器初始化部分。AMDGPU 寄存器初始化与ELF文件分析
设置好flat_scratch之后,硬件会自动完成(2),(3),(4)的计算与求和,得到最终的global地址。我们来做个实验验证上述过程,
实验代码如下:
#include <hip/hip_runtime.h>
#include <stdio.h>
// 使用__noinline__ 构造flat指令
__device__ __noinline__ bool isPrivate(const __attribute__((address_space(0))) void *addr) {
return __builtin_amdgcn_is_private(addr);
}
__global__ void test(int *in, int *out) {
long long A = 0x12345678deadbeaf; // A 8字节占用2个element,高32bit是0x12345678, 低32bit是0xdeadbeaf
long long private_base;
long long private_size;
long long scratch;
asm volatile("s_mov_b64 %0, src_private_base" : "=rr"(private_base));
asm volatile("s_mov_b64 %0, src_private_limit" : "=rr"(private_size));
asm volatile("s_mov_b64 %0, flat_scratch" : "=rr"(scratch));
if (threadIdx.x == 0) { // 打印private的aperture以及falt_scratch地址
printf("private base %llx limit %llx flat scratch %llx\n", private_base, private_size, scratch);
printf("&A is %p\n", &A);
}
*out = isPrivate((const __attribute__((address_space(0))) void *)&A); // 将A的地址传入device函数
}
int main() {
int *d_in, *d_out;
hipMalloc((void**)&d_in, sizeof(int)*10);
hipMalloc((void**)&d_out, sizeof(int)*10);
test<<<1,64>>>(d_in, d_out);
int v;
hipMemcpy(&v, d_out, sizeof(int), hipMemcpyDeviceToHost);
printf("v is %d\n", v);
}
代码中,我们用了一个isPrivate device函数判断一个地址是否是private的,这里主要是用来断点的,没啥特殊作用。test kernel中定义了一个待观察的8字节变量A,值被设置为一个特殊的0x12345678deadbeaf,A占用两个element,所以其global address是不连续的,另外kernel还定义了几个变量记录private aperture的baes、limit以及flat_scratch寄存器的值。在host中,我们启动了一个wavefront来运行test kernel。
编译后,我们在isPrivate处设置断点,观察private apertue的base与limit,以及A变量的地址:
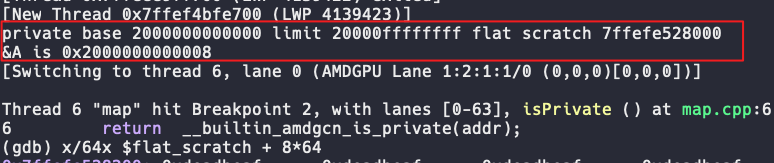
可以看到A相对private的偏移是8字节,那么A的低4字节的global地址就是flat_scratch + 8*64,并且该处是64个线程各自的A变量。对应的,A的高4字节的global地址就是flat_scratch + 12*64:
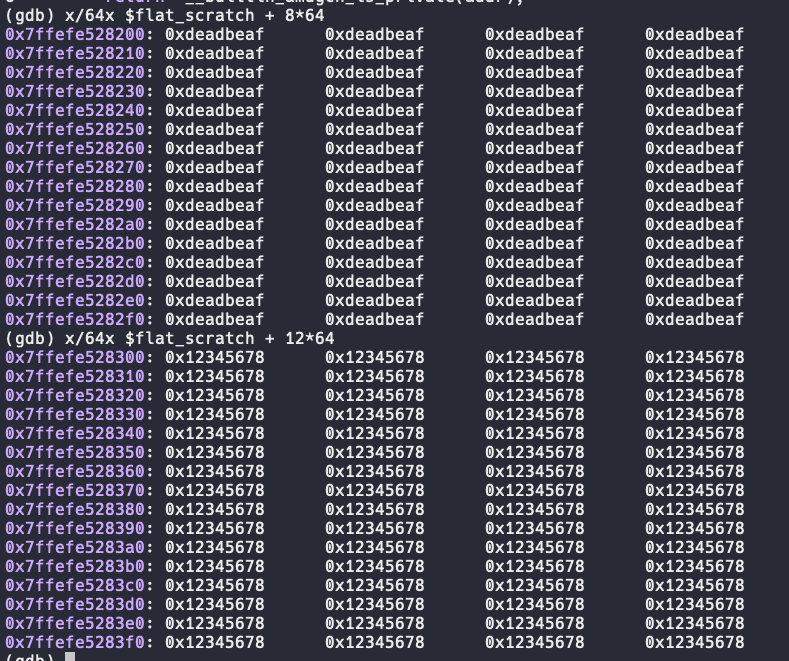
可以看到,实验结果完全符合预期!
我们再来做个实验看下每个wavefront的flat_scratch是否符合公式(1),实验代码如下:
#include <hip/hip_runtime.h>
__device__ __noinline__ void foo(void *x) { // noinline 保证生成flat指令,因此编译器会在prolog设置flat_scratch值。
int y = *(int *)x;
printf("y is %d\n", y);
}
__global__ void test(int *in, int *out) {
foo(in);
int buf[1000]; // 定义一个大的private变量
for (int i = 0; i < 1000; i++)
buf[i] = in[i] * in[i] + out[i];
for (int i = 0; i < 10; i++)
out[i] = buf[i] + buf[i];
long long flat_scratch;
asm volatile("s_mov_b64 %0, flat_scratch": "=rr"(flat_scratch)); // 获取flat_scratch值
if (__lane_id() == 0) {
printf("wave %d flat_scrach is 0x%llx\n", threadIdx.x/64, flat_scratch); // 打印每个wavefront的flat_scratch
}
}
int main() {
int array[1000] = {0};
int *d_in, *d_out;
hipMalloc((void**)&d_in, sizeof(int)*1000);
hipMalloc((void**)&d_out, sizeof(int)*1000);
hipMemcpy(d_in, array, sizeof(array), hipMemcpyHostToDevice);
test<<<1, 640>>>(d_in, d_out); // 10个wavefront
hipMemcpy(array, d_out, sizeof(array), hipMemcpyDeviceToHost);
}
编译运行后输出如下:
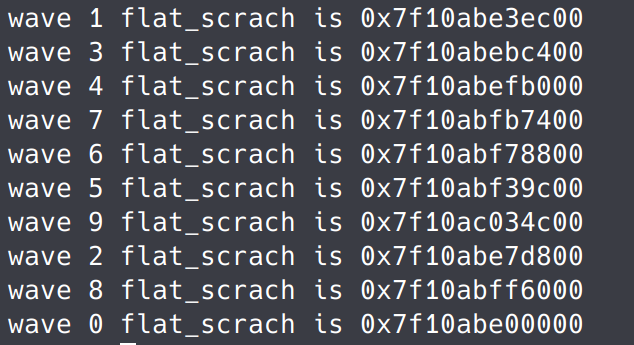
可以看到各wavefront的距离都是0x3ec00,也就是257024字节。我们在device的.s汇编文件中可以得到scratch_size,在本例中其大小为4016字节:
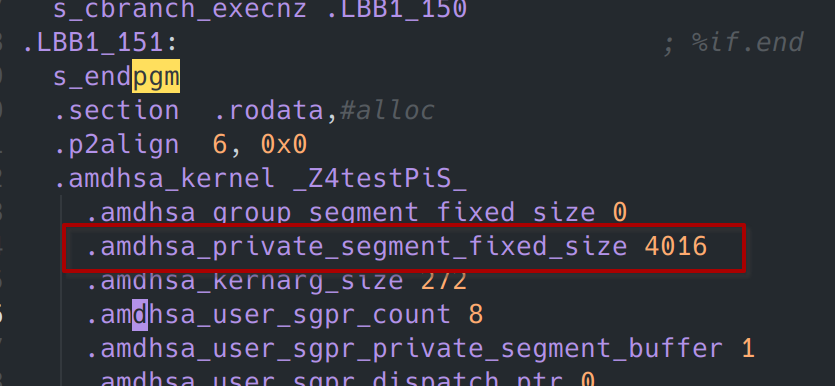
而\(scratch\_size * wavefront\_size = 4016* 64 = 257024\)。与公式完全符合!
3.2 Global空间
global使用global虚拟地址空间,该虚拟地址空间与CPU是一致的,都是48位,这是因为大部分64位CPU都使用48位地址线。虽然共用同一块地址空间,但是有些部分只能CPU访问,有的部分只能GPU访问,有的部分两者皆可访问。我们目前只需要关心GPU能访问的部分即可,由于这块区域对应GPU的device memory,因此是设备内共享的,可以基于global memory实现grid级别的同步。
3.3 Region空间
region地址空间使用硬件的GDS内存,该内存位于片上,比global memory更加高效,并且该区域由所有CU共享,因此可以实现设备级的同步与共享。但是HIP/CUDA的编程语言规范中并没有操作该区域的语法,需要使用汇编指令,因此并不常用。
3.4 Local空间
local地址空间使用硬件的LDS内存,该内存位于片上,具有与work-group(也就是常说的block)相同的生命期。创建一个work-group时,硬件会自动分配一段LDS上的内存作为share memroy使用。当work-group内所有wavefronts结束时,该内存释放。
3.5 Constant空间
constant空间物理上与global空间一致,该地址空间的内容在kernel执行期间是不变的,只有host侧能对其进行修改。比如我们执行的kernel指令、一些runtime维护的数据结构(如AQL数据包)、kernel的参数等都属于constant空间。constant空间内的值可以使用 SMEM(scalar memory)指令对其进行加载,并且使用constant cache(见图1,也称为scalar L1 cache)对值进行缓存,当启动新kernel时,该cache会被无效掉。
3.6 Private空间
private空间使用硬件上的scratch memory,具有wavefront的生命期,当硬件创建一个wavefront时,会为其自动分配一段scratch memory,当wavefront执行结束时,自动释放该内存。实际上,当runtime向硬件下发一个kernel时,会从global memory中分配一个后备内存池,并将地址传递给硬件,供硬件作为scratch memory(private segment buffer)使用。在scratch memory中,各线程私有变量以swizzled的方式进行布局,细节参见Generic空间一节。
对private空间的访问有两种寻址方式:
- flat/scratch 寻址。通过在kernel prolog中设置flat_scratch寄存器,kernel可以通过flat address来访问位于private segment buffer中的线程私有变量。硬件会自动将flat address转为global address。
- buffer 寻址。GPU在内核执行前往一些寄存器中写入rivate_segment_buffer的述符(一般位于s[0-3]),之后就可以使用buffer指令来访问private空间中的局变量。具体方式参见后面的buffer寻址一节。
4. 访存指令类别
AMDGPU的访存总体上可以分为标量访存(SMEM)、向量访存(VMEM)与DS访存。标量访存指wave内所有线程需要访问的数据一致,通过SGPR与内存传输数据的访存;而向量访存则指wave内各线程的访存相互独立,通过VGPR与内存传输数据的访存;DS访存则指对LDS/GDS的访问操作。向量访存指令根据寻址方式与访问对象的不同,可细分为buffer指令、Image指令与flat指令(包括flat、global、scratch)。下面分别介绍:
4.1 标量访存(Scalar Memory Operations)
标量访存允许kernel程序通过constant cache将global memory上的数据加载到SGPR中(见图1的数据通路),最多可加载16个DWORDs。该类指令主要用于加载常量数据,如kernel参数(位于constant memory)。
在CDNA架构中,标量访存不仅包含load指令,还包括store指令。如s_store_dword,s_scratch_store等,但是在编译器中并没有store指令的pattern,因此除了使用汇编外,编译器不会生成此类指令。
由于SMEM主要被设计为加载常量,而常量内存在kernel执行期间并不会被修改,因此从设计的角度也并不需要这种指令。在后续的指令集架构中(如RDNA3),已经去除了store指令。
1.寻址方式
SMEM指令有scalar memory寻址与buffer寻址两种。scalar memory寻址公式如下:
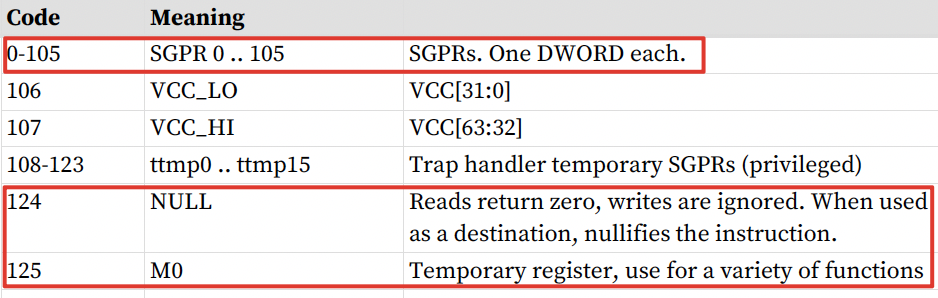
\[ADDR = SGPR[base] + inst\_offset + \{M0 \ or \ SGPR[offset] \ or \ zero\}\]其中SGPR[base]来源于指令的SBASE字段,inst_offset来源于OFFSET字段,M0/SGPR[offset]/zero来源于SOFFSET字段。SOFFSET是寄存器类型,不同编码对应不同寄存器:
buffer寻址依赖于buffer 资源常亮描述符(文档中记为v#)。v#由4个连续SGPR组成,起始寄存器为SBASE。计算SMEM地址依赖于v#中的3个成员:base_address, stride, num_records。stride与num_records主要参与内存地址越界检查。计算公式与普通scalar寻址一致,只是base由v#中的base字段描述。后面会有buffer寻址的详细介绍。
2.注意事项
- 对于2个DWORDs的load,SDST寄存器(目标寄存器)编号需要是偶数对齐,对于更大数据类型的load,则要求编号是4的倍数。
- 对于s_buffer_load指令,其SBASE寄存器编号需要是偶数。(到底是偶数还是4的倍数?需要验证下)
4.2 向量访存
有关向量访存,RDNA3 ISA手册中描述得很优雅:
Vector-memory (VM) buffer operations transfer data between the VGPRs and buffer objects in memory through the texture cache (TC). Vector means that one or more piece of data is transferred uniquely for every thread in the wave, in contrast to scalar memory loads that transfer only one value that is shared by all threads in the wave.
在RDNA3 ISA中,向量访存指令被分为buffer、image与普通flat/global/sratch。由于image指令和大部分buffer指令主要和图形学相关,我们在这不对其进行细致介绍,仅介绍下buffer的寻址方式,帮助读者了解AMDGPU通过buffer指令访问scratch的机制。
1.buffer寻址
buffer是内存中的一种数据结构,可以简单地认为是结构数组。每个结构被称作一个记录(record),由若干个element组成(结构体成员),element大小可以是1,2,4,8,12,或16字节(scratch buffer中element_size是4字节)。buffer寻址可以由(index, offset, stride)三元组表示。其中index是结构数组的下标,offset是一个结构内的偏移,stride是结构的大小(就是记录的大小)。
对具体的buffer指令,其地址由以下三部分相加:
- 基地址(const_base),来源于v#
- sgpr offset,来源于指令
- buffer-offset,需要计算。
根据buffer是否被swizzled,buffer-offset的计算有所差异,但都需要获取index与offset,index与offset的计算公式如下:
\[Index = (\textcolor{red}{inst\_idxen} ? vgpr\_index : 0) + (\textcolor{red}{const\_add\_tid\_enable} ? workitemID : 0)\] \[Offset = (\textcolor{red}{inst\_offen} ? vgpr\_offset : 0) + inst\_offset\]其中inst_idxen与inst_offen是指令中的两个控制bit,const_add_tid_enable是buffer描述符的一个控制位。vgpr_index与vgpr_offset是指令中的vgpr,inst_offset则是指令中的立即数字段。确定好index与offset后,可以直接计算linear buffer的buffer-offset:
\[buffer\_offset = offset + stride * index\]整个过程可以参考图13。

如果buffer描述符中const_swizzle_enable字段显示是swizzled buffer,则buffer-offset有所不同。具体参考下图:

其中const_index_stride表示连续多少个stride参与swizzling,const_stride表示一个stride的大小。在scratch memory中,const_index_stride是wavefront_size,const_stride是scratch_size,element_size是4,index其实就是thread_id,offset指在private空间中的偏移(flat地址中private aperture中的偏移)。感兴趣的读者可以将这些信息代入到上面的公式感受下这个计算过程。
2.buffer描述符(v#)格式

4.3 DS访存
TODO
参考文献
- RDNA3 ISA手册 (强烈推荐)
- CDNA ISA手册(很多错误,建议对比RDNA3看)
- LLVM AMDGPUUsage
- CDNA白皮书