AMDGPU 发散分析与scalar/vector指令生成
1. 引言
在AMDGPU中,指令可分为scalar与vector两类。scalar指令对wavefront内所有线程一致,而vector指令维护wave内每个线程的状态并实施各自的运算。这种设计的好处是,可以只将线程相关的操作交付向量部件(VALU),而将线程无关的操作交给scalar指令运行,从而达到共享、节约硬件资源的目的。那么HIP代码什么时候会被编译为scalar指令,什么时候又会被编译为vector指令呢?本文将进行解答。
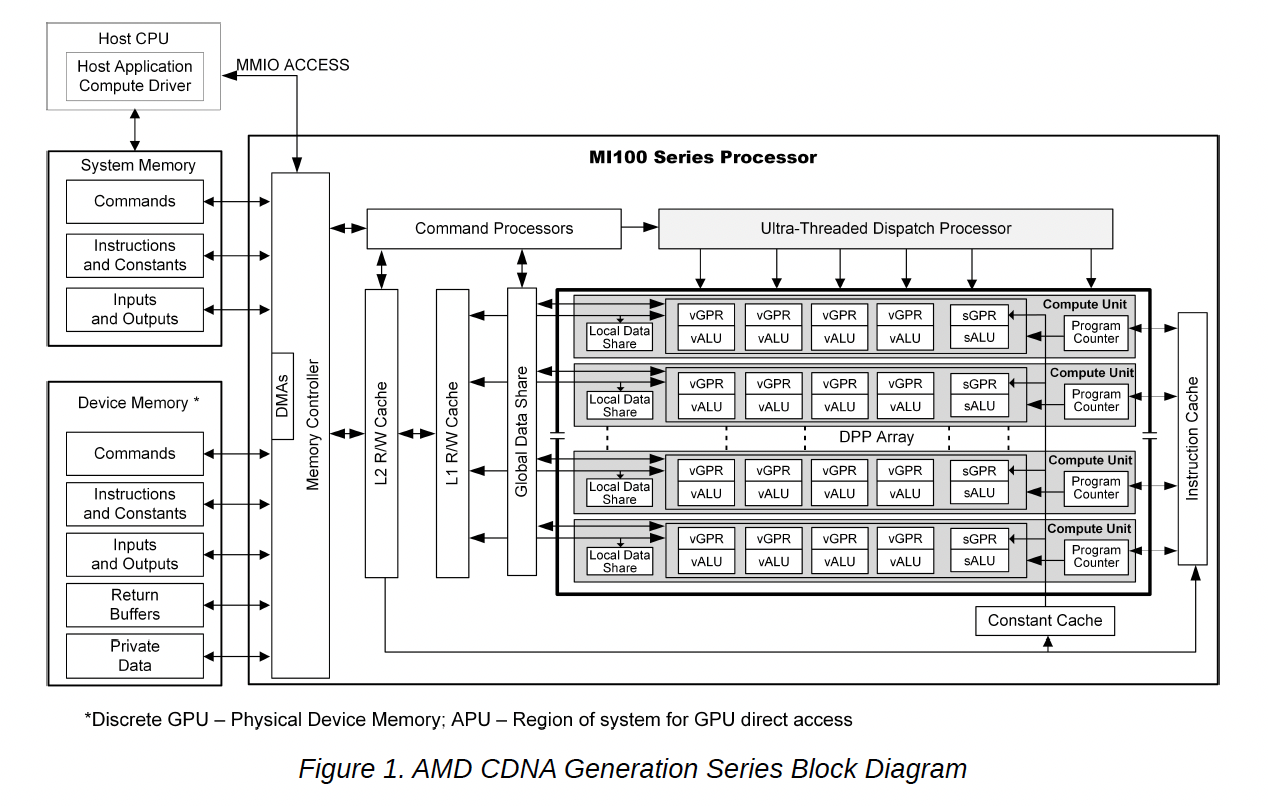
2. Divergence Analysis
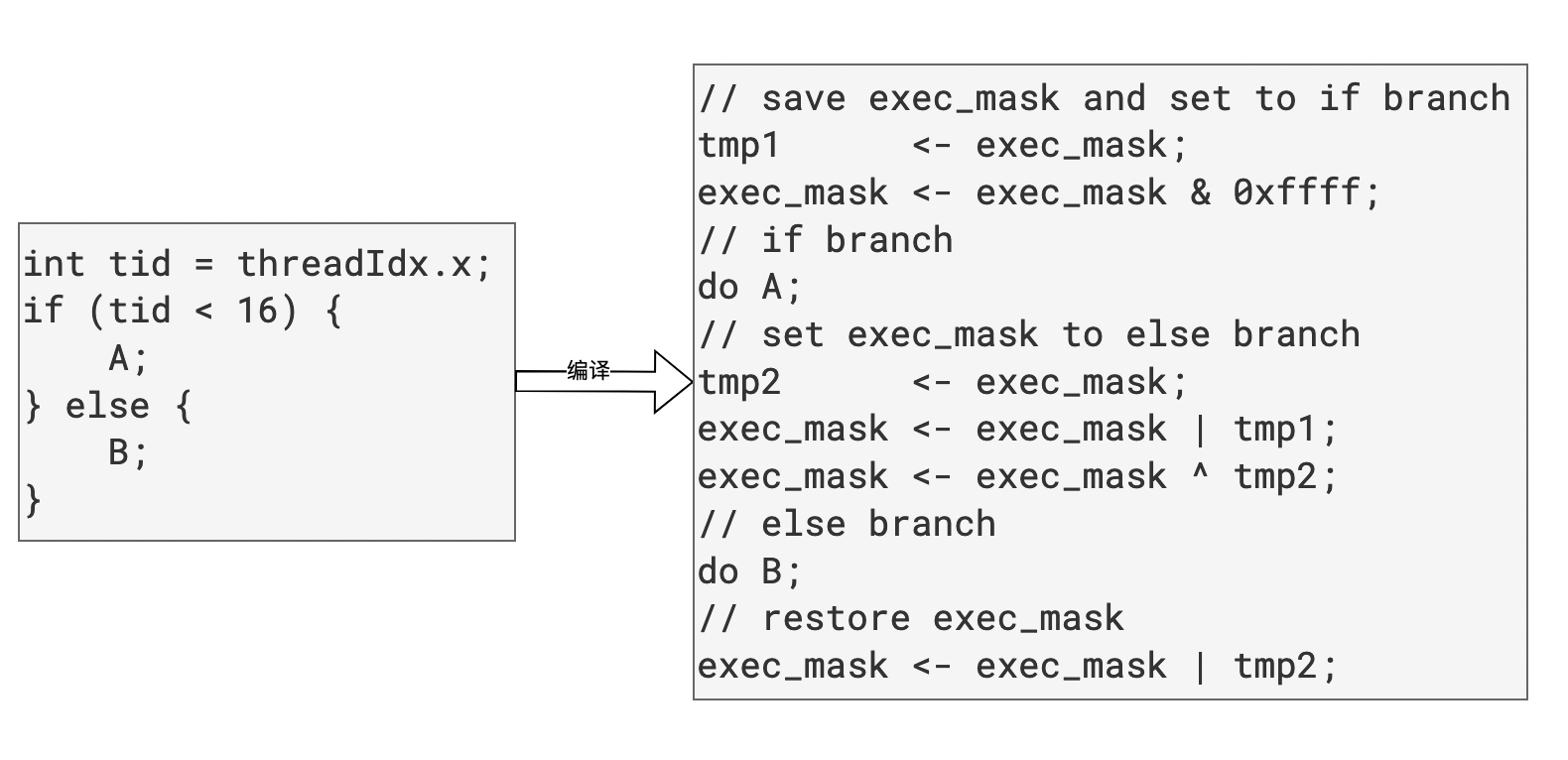
在AMDGPU中,指令按照SIMT的方式运行,由若干(32/64)线程组成wavefront执行相同的PC。如果一个值对于wavefront内所有活跃线程都是相同的,则称该值是一致的(uniform),否则为发散的(divergent)。相应地,如果一条分支指令的条件(也称谓词)是发散的,那么该分支就是发散分支,在这种情形下,wavefront内的线程需要执行不同的路径,编译器需要设置exec_mask、遍历所有路径来保证代码的正确性。
静态分析中,识别值的发散性称为发散分析(Divergence Analysis)。发散分析对于AMDGPU编译器非常重要,它可以辅助编译器选用哪类指令,也可以作为后续发散控制流处理的基础。LLVM中通过LegacyDivergenceAnalysis这一function pass来完成IR的发散性分析。该pass位于llvm-project/llvm/lib/Analysis/LegacyDivergenceAnalysis.cpp,代码非常简单,非常适合水文章学习。下面将介绍该pass的算法。
2.1 发散源(source of divergence)
我们先来看下发散源。发散源是一类特殊的IR,它门所产生的值是恒定发散的,不依赖操作数。在AMDGPU中,大致有如下发散源:
- private与flat的load指令:private是线程私有的,因此其值可认为是发散的;flat能访问private,因此也保守认为发散。
- 原子指令:针对同一地址的原子指令返回值是发散的。
- 读取vgpr、vcc的intrinsic。
- 其他一些特殊的intrinsic,如threadIdx.x/y/z等,
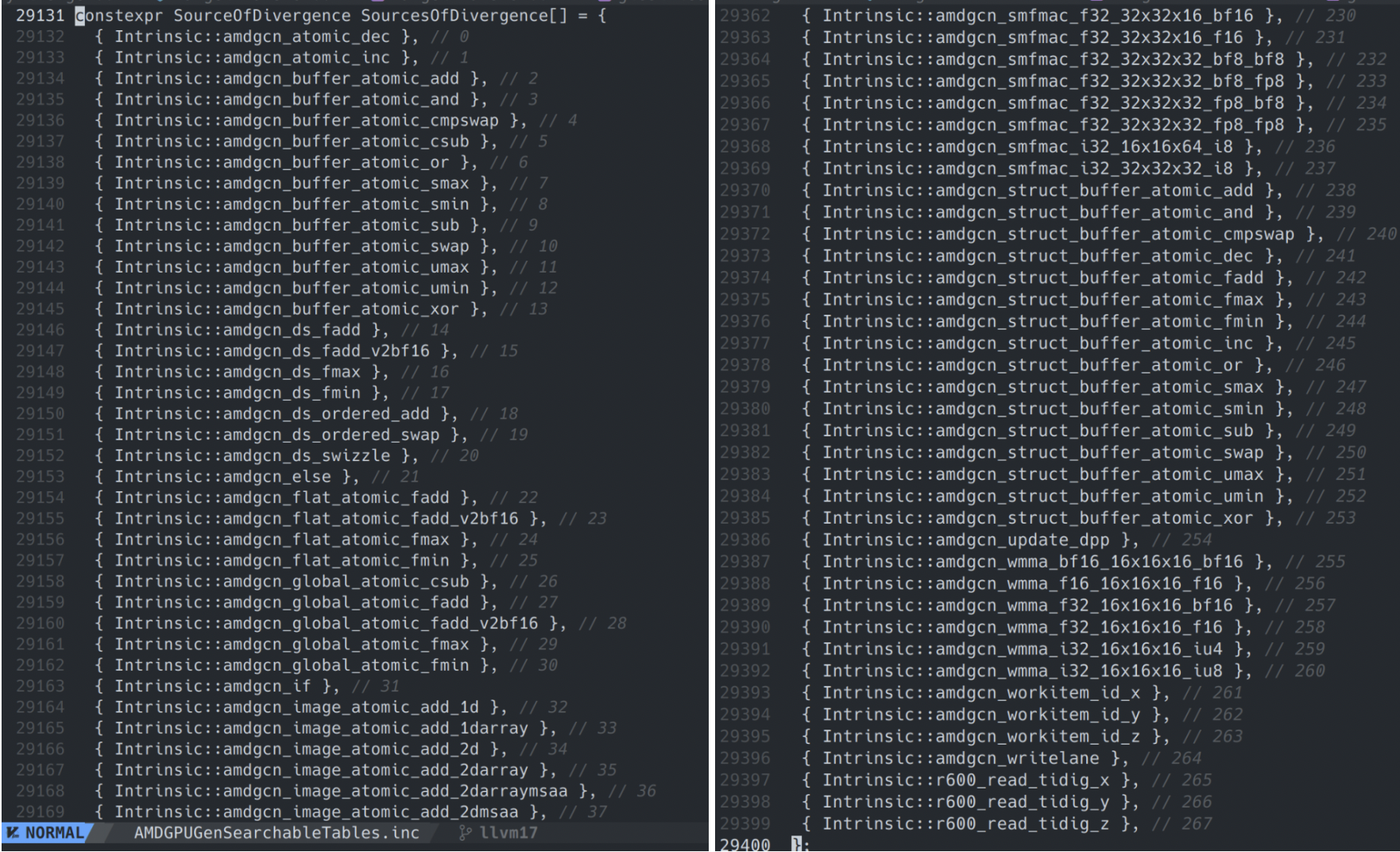
- 所有函数调用:该pass是过程内的,对于跨函数调用都保守地认为是发散的。
2.2 数据依赖(DataDependency)与同步依赖(SyncDependency)
2.2.1 定义
识别出发散源后,可以通过对发散源进行依赖分析,挖掘出其他的发散值。新识别出的发散值作为新的发散源继续此过程,直到发散值集合收敛(典型的不动点算法)。
挖掘其他发散值是基于数据依赖与同步依赖分析完成的:
- 数据依赖:根据def-use chain,如果def是一个发散值,其user如果不是uniform的(比如readlane),那么use就是一个新的发散值。
- 同步依赖:与数据依赖根据d-u chain进行分析不同,同步依赖根据发散值对控制流的影响,进而影响其他值的发散性。看下面示例:
if (tid < 5)
a1 = 1;
else
a2 = 2;
a = phi(a1, a2); // a 同步依赖于 tid < 5
此例中a与tid没有数据依赖,但是tid通过影响控制流,使得不同线程获得的a不同。因此a也是一个发散值,并且同步依赖于tid < 5。可以通过对发散分支进行同步依赖分析,挖掘新的发散值。
另外,同步依赖还有一种情形:
int i = 0;
do {
i++;
if (foo(i)) ... // 循环内i是uniform的,注意uniform是针对活跃线程而言。
} while (i < tid);
if (bar(i)) ... // 循环外i是发散的
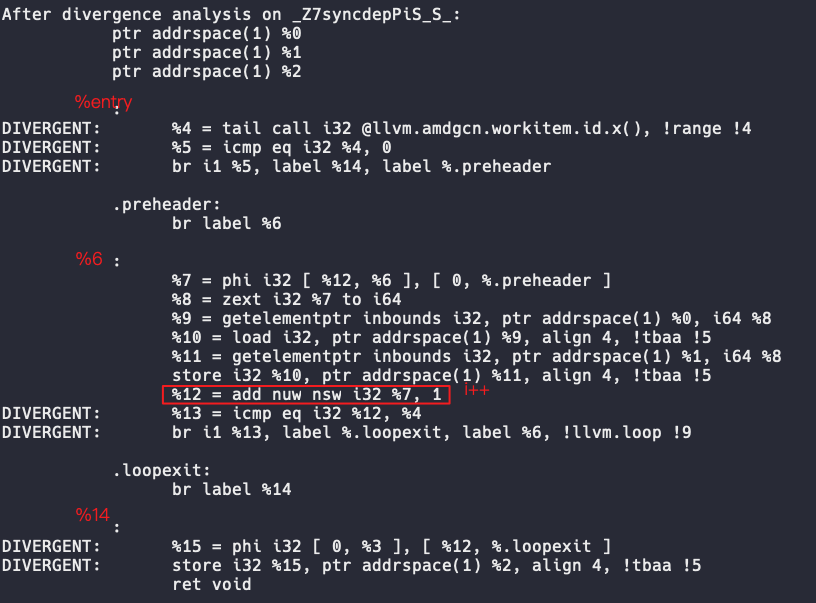
在syncdependency2中,i在循环内部是uniform的,因为任何活跃线程的值都是相同的,并且i不数据依赖其他发散值。但是不同线程执行循环的次数不同,循环退出时i的值也不同,因此循环外的i同步依赖于i < tid。下图展示了一段含循环的IR的发散性,其中的%15就是同步依赖于i < tid的。
2.2.2 挖掘数据依赖
给定一个发散值V,通过对V进行数据依赖分析挖掘新的发散值的过程如下:
遍历V的def-use chain,分析chain中的每个Use,如果不是unform的,则将该Use放入发散值集合中。
LLVM中对应代码如下:
void DivergencePropagator::exploreDataDependency(Value *V) {
// Follow def-use chains of V.
for (User *U : V->users()) {
if (!TTI.isAlwaysUniform(U) && DV.insert(U).seconde) // 非恒uniform的U插入DV发散值集合
Worklist.push_bakc(U); // 把U放入工作链表,继续对U进行依赖分析
}
}
2.2.3 挖掘同步依赖
如前所述,同步依赖有两种情形:
- 对于发散分支的immediate post dominator基本块,如果该基本块的phi指令不是constant的(无论前驱为何,value都一致),那么该phi就会同步依赖发散分支。因此可以用下面的代码进行判断:
BasicBlock *ThisBB = ti->getParent(); // 条件分支所在基本块
DomTreeNode *ThisNode = PDT.getNode(ThisBB); // 后支配树中对应的节点
BasicBlock *IPostDom = ThisNode->getIDom()->getBlock(); // thisblock的直接后支配节点
for (auto I = IPostDom->begin(); isa<PHINode>(I); ++I) { // 遍历直接后支配节点的phi指令
if (!cast<PHINode>(I)->hasConstantOrUndefValue() && DV.insert(&*I).second) // 指令是非constant的phi,则放入发散值集合
Worklist.push_back(&*I); // 将phi放入工作链表,继续依赖分析
}
- 对于在循环内部定义且在循环外被使用的变量,user会同步依赖于循环退出条件(loop exits,也是发散分支)。算法分为两个步骤:
- 找出loop exits的影响区域。
- 找出影响区域内def且被区域外use的值。该值的user就是新的发散值。
影响区域是从loop exit到其immediate post dominator的所有简单路径的并集。比较直观的感受就是循环内的基本块。下图中演示了影响区域的两个示例。左边的示例中,A是loop exit(也是loop head),F是其immediate post dominator;该图右边的示例中,Z是loop exit,P是其immediate post dominator。示例中的蓝色基本块是两者的影响区域:
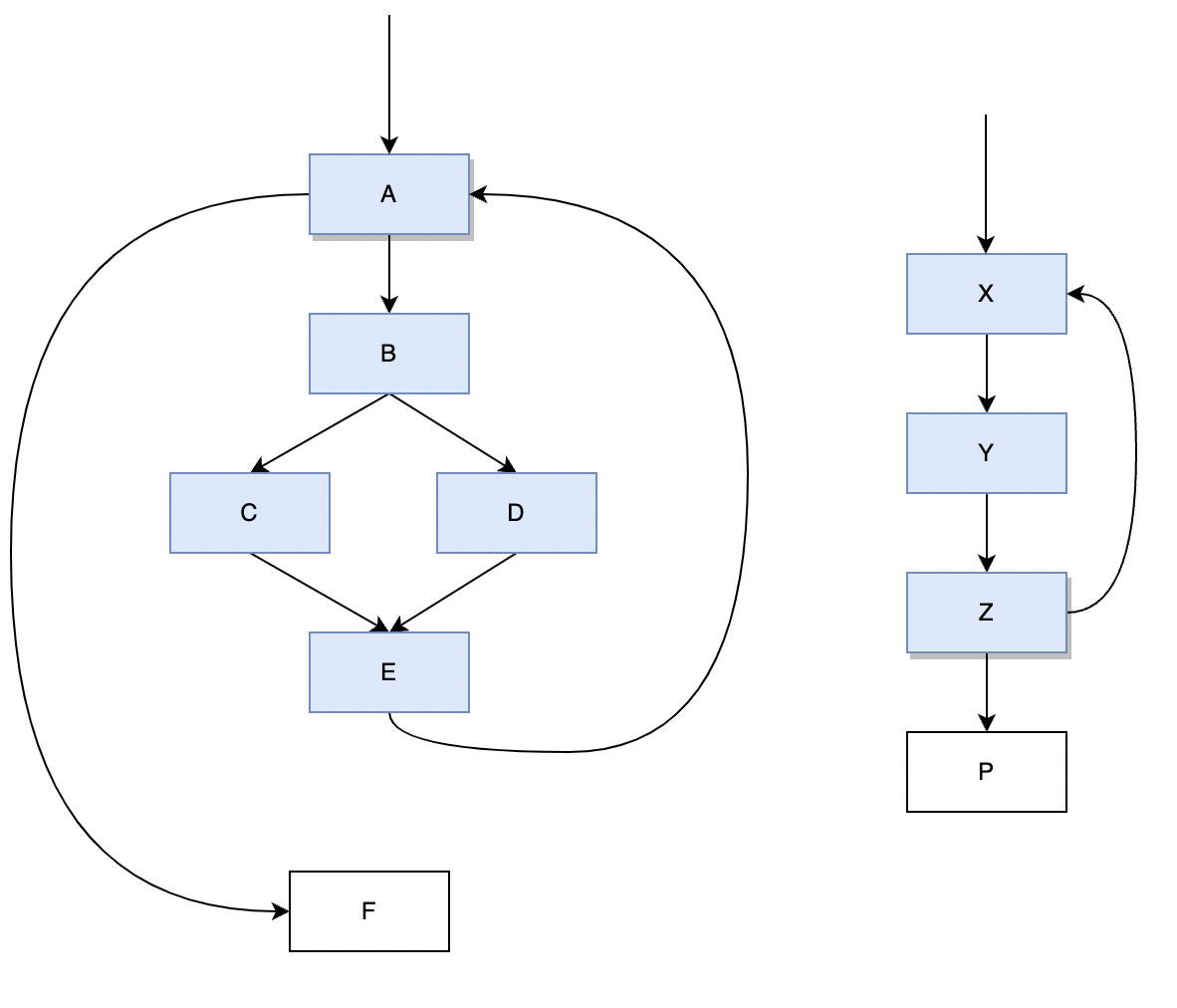
计算影响区域就是一个简单的DFS:
// 辅助函数,将ThisBB的后继加入影响区域,后继不能是immedate post dominator(End)
void addSuccessorsToInfluenceRegion(BasicBlock *ThisBB, BasicBlock *End, DenseSet<BasicBlock *> &InfluenceRegion,
std::vector<BasicBlock *> &InfluenceStack) {
for (BasicBlock *Succ : successors(ThisBB)) {
if (Succ != End && InfluenceRegion.insert(Succ.second) // End是immediate post dominator
InfluenceStack.push_back(Succ);
}
}
// 计算影响区域, start是loop exit, End是immediate post dominator,结果位于InfluenceRegion中
void DivergencePropagator::computeInfluenceRegion(BasicBlock *Start, BasicBlock *End,
DenseSet<BasicBlock *> &InfluenceRegion) {
std::vector<BasicBlock *> InfluenceStack; // 基于栈的dfs
addSuccessorsToInfluenceRegion(Start, End, InfluenceRegion, InfluenceStack); // 初始化栈
while (!InfluenceStack.empty()) { // dfs启动
BasicBlock *BB = InfluenceStack.back();
InfluenceStack.pop_back();
addSuccessorsToInfluenceRegion(BB, End, InfluenceRegion, InfluenceStack);
}
}
要找出区域外使用的值,一种简单的做法就是遍历区域内的基本块,然后判断基本块内每条指令是否被循环外使用。但是这种做法效率不高。
以图一为例。普通算法需要遍历A,B,C,D,E 5个基本块的指令,但是实际上我们只需要检查A基本块即可。因为B,C,D,E不支配A,所以B,C,D,E中def的value在A处(dominator frontier)会成为phi的incoming value,直接分析A中的phi是否被区域外使用即可。
那么最少需要检查哪些基本块呢?答案就是支配loop exit的基本块。我们从包含loop exit块开始,遍历支配树上的直接支配节点,直至新的基本块不在影响区域即可停止。如图一的右例中,我们先分析Z中的值,然后分析其直接支配Y,再分析Y的直接支配X,最后发现X的直接支配出了影响区域即停止。
LLVM中算法实现如下:
DenseSet<BasicBlock *> InfluenceRegion;
computeInfluenceRegion(ThisBB, IPostDom, InfluenceRegion); // 计算影响区域
BasicBlock *InfluencedBB = ThisBB;
while (InfluenceRegion.count(InfluencedBB)) { // 位于区域内
for (auto &I : *InfluencedBB) { // 遍历该BB指令
if (!DV.count(&I))
findUsersOutsideInfluenceRegion(I, InfluenceRegion); // 挖掘被外部使用的value
}
// 更新InfluencedBB 为其直接支配节点
DomTreenode *IDomNode = DT.getNode(InfluencedBB)->getIDom();
if (IDomNode == nullptr) break;
InfluencedBB = IDomNode->getBlock();
}
}
2.3 算法流程
了解了发散源、数据依赖以及同步依赖后,DA的算法就比较清晰了。算法首先识别IR中的发散源,放入工作链表中,之后不断从工作链表中取出IR,实施数据依赖与同步依赖分析,挖掘新的发散值。新的发散值也会被放入工作链表中,重复此过程,直至最终记录发散值的集合收敛(工作链表为空),算法结束。
- 识别发散源
void DivergencePropagator::populateWithSourcesOfDivergence() {
Worklist.clear(); // 初始化工作链表
DV.clear(); // 初始化发散值集合
DU.clear();
for (auto &I : instructions(F)) { // 遍历指令,识别发散源
if (TTI.isSourceOfDivergence(&I)) {
Worklist.push_back(&I);
DV.insert(&I);
}
}
for (auto &Arg : F.args()) { // 遍历函数参数,识别发散源(部分入参位于vector寄存器,也是发散源)
if (TTI.isSourceOfDivergence(&Arg)) {
Worklist.push_back(&Arg);
DV.insert(&Arg);
}
}
}
- 实施依赖分析
void DivergencePropagator::propagate() {
// Traverse the dependency graph using DFS.
while (!Worklist.empty()) {
Value *V = Worklist.back();
Worklist.pop_back();
if (Instruction *I = dyn_cast<Instruction>(V)) { // 如果是满足条件的发散分支,实施同步依赖分析
// Terminators with less than two successors won't introduce sync
// dependency. Ignore them.
if (I->isTerminator() && I->getNumSuccessors() > 1)
exploreSyncDependency(I);
}
exploreDataDependency(V); // 实施数据依赖分析
}
}
3. 指令选择与DivergenceAnalysis
前面已经介绍了LegacyDivergenceAnalysis这一pass的算法流程,该pass可分析IR中值的发散性。本节我们将继续分析发散性对LLVM后端指令选择的影响。
LLVM后端从SelectionDAGISel这一pass开始。该pass首先会将IR转为一个选择DAG,之后会在DAG上执行Legalize,消除图上不支持的数据类型与操作,接着再执行指令选择。选择完后的指令调度、寄存器分配将不再受发散性的影响。因此下面我们将重点关注:
- SelectionDAG 中的SDNode是如何携带发散信息。
- 以及指令选择如何匹配带发散信息的SDNode。
3.1 SDNode中的发散信息
SDNode中含有一个SDNodeBits的成员,该成员的类型如下:
class SDNodeBitfields {
friend class SDNode;
friend class MemIntrinsicSDNode;
friend class MemSDNode;
friend class SelectionDAG;
uint16_t HasDebugValue : 1;
uint16_t IsMemIntrinsic : 1;
uint16_t IsDivergent : 1; // 标识该SDNode是否是divergent的
};
其中的IsDivergent即用于标记该SDNode的发散属性。我们可以写一段AMDGPU的IR,然后用llc -debug编译该IR,观察输出日志中SDNode的信息。AMDGPU IR如下:
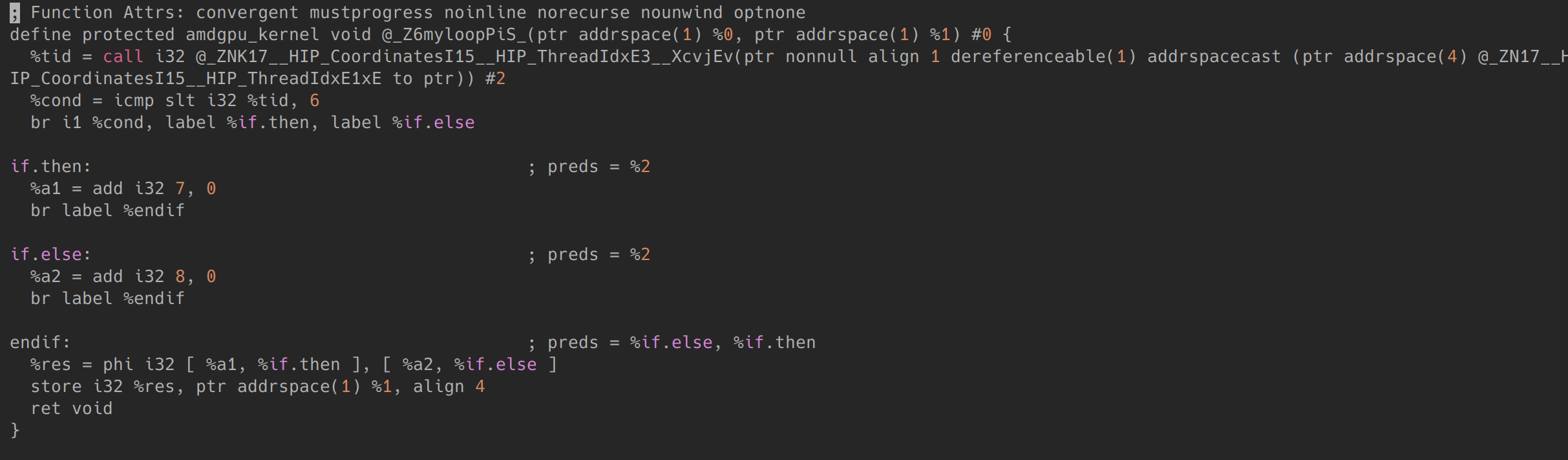
该IR基本与SyncDependence1实例代码相同。该IR让tid < 6的线程进入if.then,其他线程进入if.else。endif中res是一个divergent value并同步依赖于tid < 6。编译后观察endif基本块的SDNode如下:
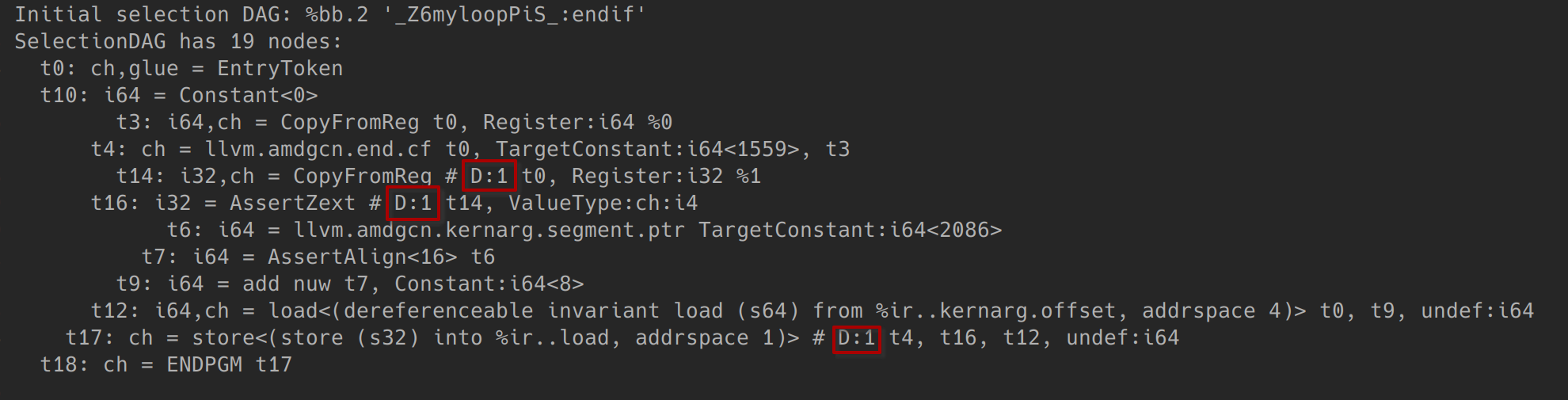
可以看到,t14、t16与t17是Divergent的。要理解SDNodeBits.IsDivergent是如何被设置的,可以阅读SelectionDAG::createOperands。该函数给新建的SDNode设置输入操作数,同时也设置该SDNode的发散属性:
// 给Node设置输入操作数为Vals
void SelectionDAG::createOperands(SDNode *Node, ArrayRef<SDValue> Vals) {
...
// 分配操作数内存
SDUse *Ops = OperandRecycler.allocate(
ArrayRecycler<SDUse>::Capacity::get(Vals.size()), OperandAllocator);
bool IsDivergent = false;
// 如果操作数是Divergent的,那么给Node也设置Divergent
for (unsigned I = 0; I != Vals.size(); ++I) {
Ops[I].setUser(Node);
Ops[I].setInitial(Vals[I]);
if (Ops[I].Val.getValueType() != MVT::Other) // Skip Chain. It does not carry divergence.
IsDivergent |= Ops[I].getNode()->isDivergent();
}
Node->NumOperands = Vals.size();
Node->OperandList = Ops;
// 如果Node是一个发散源,则设置其为Divergent
if (!TLI->isSDNodeAlwaysUniform(Node)) {
IsDivergent |= TLI->isSDNodeSourceOfDivergence(Node, FLI, DA);
Node->SDNodeBits.IsDivergent = IsDivergent;
}
checkForCycles(Node);
}
在该函数中,如果SDNode的任意一个操作数是Divergent的,那么就设置该SDNode为Divergent。这就是上例中t16,t17被置为Divergent的原因,t16中的操作数t4是发散的,t17的操作数t16是发散的。
另外,如果该SDNode是发散源,则也将其置为Divergent。我们查看下isSDNodeSourceOfDivergence的代码,观察其如何处理t4的CopyFromReg:
// KDA是IR阶段的发散分析pass
bool SITargetLowering::isSDNodeSourceOfDivergence(
const SDNode *N, FunctionLoweringInfo *FLI,
LegacyDivergenceAnalysis *KDA) const {
switch (N->getOpcode()) {
case ISD::CopyFromReg: {
/// 获取源寄存器
const RegisterSDNode *R = cast<RegisterSDNode>(N->getOperand(1));
const MachineRegisterInfo &MRI = FLI->MF->getRegInfo();
const SIRegisterInfo *TRI = Subtarget->getRegisterInfo();
Register Reg = R->getReg();
// FIXME: Why does this need to consider isLiveIn?
if (Reg.isPhysical() || MRI.isLiveIn(Reg))
return !TRI->isSGPRReg(MRI, Reg);
/// 返回源寄存器对应的IR的发散性
if (const Value *V = FLI->getValueFromVirtualReg(R->getReg())) // 获取源寄存器对应在IR阶段的值
return KDA->isDivergent(V); // 使用LegacyDivergenceAnalysis分析发散性
assert(Reg == FLI->DemoteRegister || isCopyFromRegOfInlineAsm(N));
return !TRI->isSGPRReg(MRI, Reg);
}
...
}
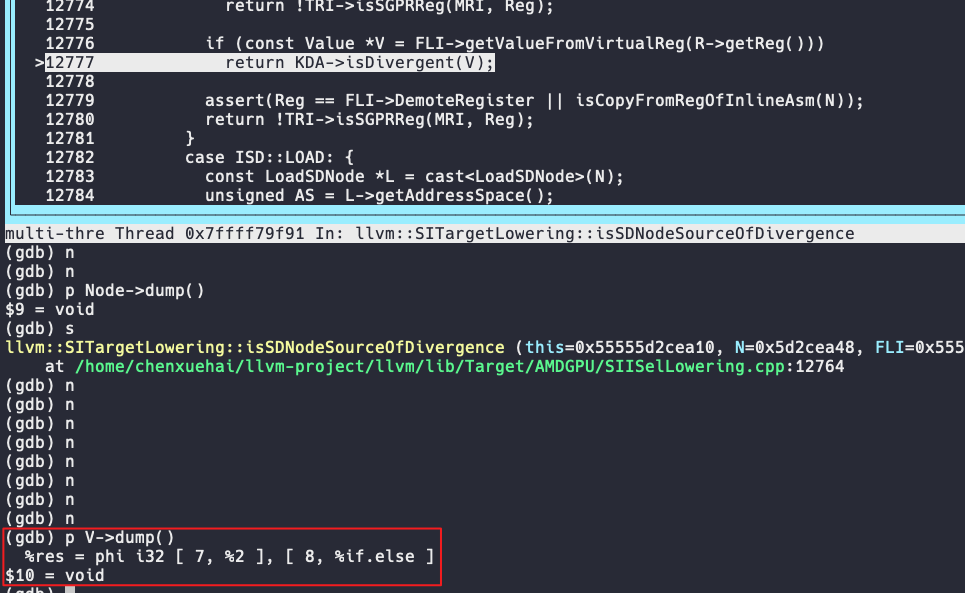
可以看到,代码首先获取源寄存器中保存的IR的值,然后使用LegacyDivergenceAnalysis判断值的发散性。在这里源寄存器保存的是endif基本块的phi值%res(见下图),因此t4也被标记为Divergent。
3.2 匹配Divergent SDNode
下面我们再来看下,指令选择是如何匹配带divergent信息的SDNode的。我们用如下示例进行演示:
__global__ void isel(int *in, int *out) {
int tid = threadIdx.x;
int v1 = in[0] + in[1]; // v1是uniform
int v2 = v1 + tid; // v2是divergent
out[0] = v1;
out[1] = v2;
}
该示例中,第一个加法的两操作数都是uniform的,所以v1也是uniform的,第二个加法由于含有发散源tid,所以是divergent的。DA分析的结果验证了这一点:
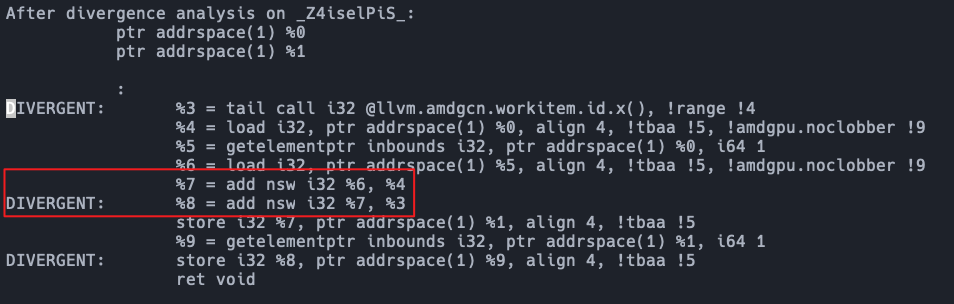
之后SelectionDAGISel将IR转为SelectionDAG,生成的两个加法SDNode一个是divergent的,另一个则是uniform的,结果如下:
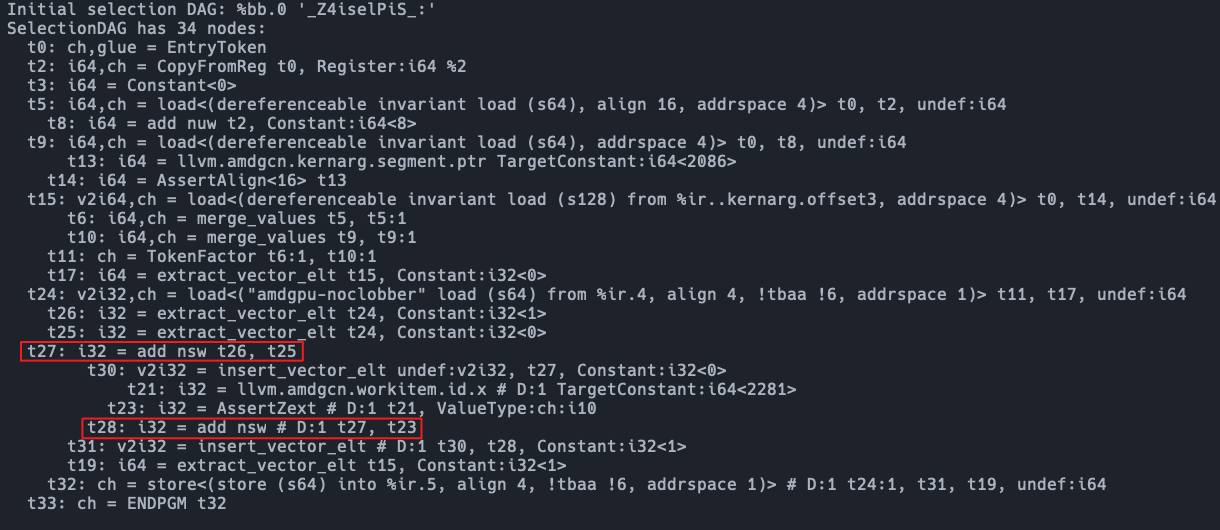
下面分析两指令的指令选择过程:
// divergent add 匹配为vector指令
ISEL: Starting selection on root node: t28: i32 = add nsw # D:1 t27, t55
ISEL: Starting pattern match
Initial Opcode index to 6
...
Match failed at index 315396
Continuing at 315454
Skipped scope entry (due to false predicate) at index 315459, continuing at 315472
TypeSwitch[i32] from 315475 to 315478
Creating constant: t64: i1 = TargetConstant<0>
Morphed node: t28: i32 = V_ADD_U32_e64 nsw # D:1 t27, t55, TargetConstant:i1<0>
ISEL: Match complete!
// unform add 匹配为scalar指令
ISEL: Starting selection on root node: t27: i32 = add nsw t26, t25
ISEL: Starting pattern match
Initial Opcode index to 6
Match failed at index 11
Continuing at 313647
Match failed at index 315396
...
Continuing at 315454
Morphed node: t27: i32,i1 = S_ADD_I32 nsw t26, t25
ISEL: Match complete!
可以看到带divergent的add SDNode被匹配为v_add,unform的SDNode被匹配为s_add。而区分选用scalar与vector的一个关键就是SDNode的发散信息,在执行匹配时会执行predict判断对应节点是否满足条件:

4. 小结
本文首先讲解了IR阶段实施发散性分析的LegacyDivergencyAnalysis pass的工作原理。然后介绍了值的发散性最终是如何影响指令选择的。现在我们可以回答引言部分的问题:对于一个value,如果它是divergent的,那么指令选择过程将会使用向量指令,反之则使用标量指令。