1. 引言
llvm中有多种分析对象,如module、function、basic block、loop、region等。前几种比较常见,在分析、优化pass中被广泛使用。而region则相对少见,但也被一些特殊的region pass所使用(如StructurizeCFG)。因此,要阅读region pass并理解其含义,需要先了解region的相关概念及使用方式。本文将介绍region的定义、llvm挖掘region并构建RegionTree的方式以及region API的一些使用。
2. Region究竟是何方神圣?
2.1 一个Region样例
我们先来直观地感受下LLVM中的region。编写一个test的C函数,使用clang -S -emit-llvm test.c -o test.ll将其编译为LLVM IR,然后用opt --view-regions-only test.ll就能得到该函数的region图:
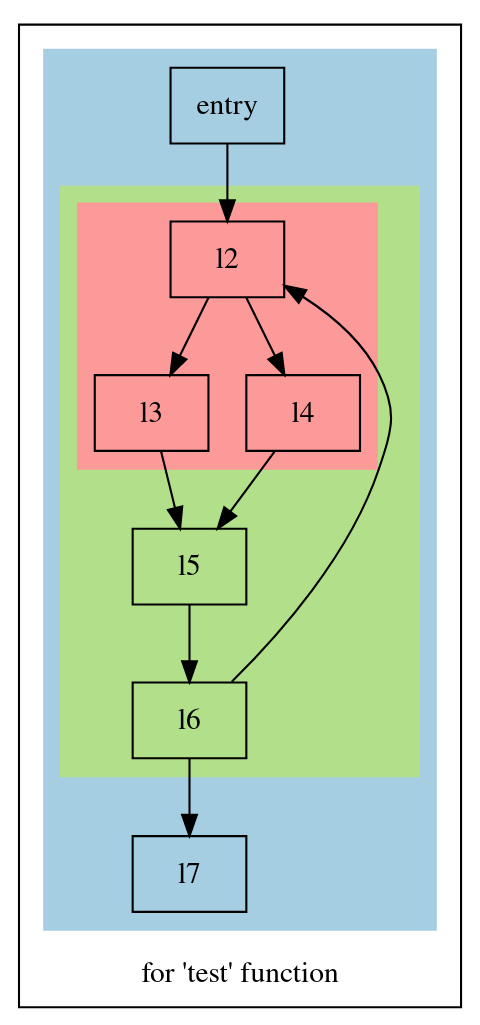
在该图中,共有红、绿、蓝三种颜色区域,表示该函数有3个region;不同颜色区域之间可以互相包含,如蓝色区域包含绿色区域,绿色区域包含红色区域,这代表了region之间的层次关系,我们称外层区域是内层区域的父区域,内层区域是外层区域的子区域。如果把控制流图(CFG)中的所有区域按照包含关系建图,那么就能得到该CFG的RegionTree了。
那么每个颜色区域有什么特点呢?有什么方式来判断一个子图是否是一个region呢?
我们观察到每个区域的入边都只连向区域内的一个固定节点(称为entry),每个区域的出边也只连向区域外的一个固定节点(称为exit)。比如红色区域有(entry, l2)、(l6,l2)两条入边,有(l3, l5)、(l4, l5)两条出边。入边都连向l2节点,出边都连向l5节点;类似地,绿色区域入边都连向l2,出边都连向l7。于是,我们基于此观察来定义LLVM中的region。
2.2 Region的定义
定义1:llvm region是CFG的一个连通子图,子图的所有入边都连向Region内的entry节点,所有出边都连向Region外的exit节点。
特别地,如果region的入边与出边都只有一条的话,就称该region为simple region,否则称为extended region。其中,extended region可以通过添加merge基本块将多条入边或者出边合并成一条来转成simple region。llvm中的相关描述如下:
A simple Region is connected to the remaining graph by just two edges. One edge entering the Region and another one leaving the Region.
An extended Region (or just Region) is a subgraph that can be transform into a simple Region. The transformation is done by adding BasicBlocks that merge several entry or exit edges so that after the merge just one entry and one exit edge exists.
将extended region转化为simple region的方式如下图所示:
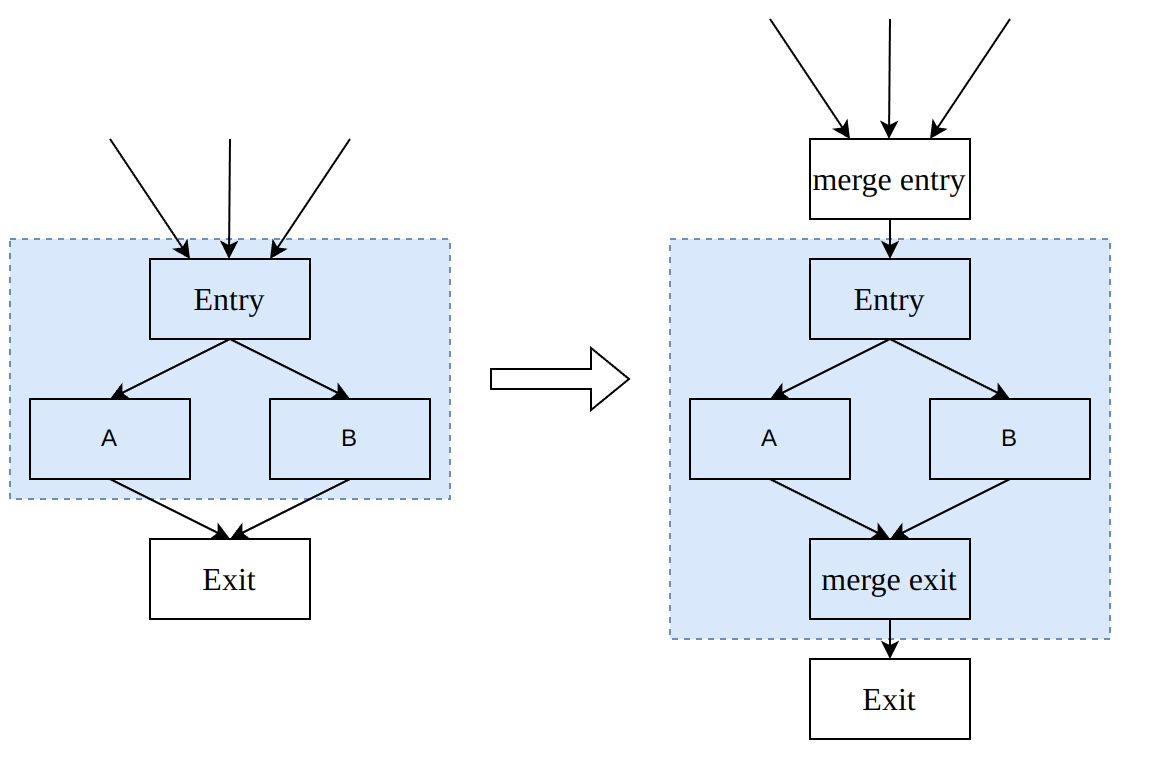
因为region的定义中最关键的是entry与exit节点,因此我们一般用(entry, exit)作为一个region的记号。如果region中只有一个节点,就称其为trival region。
2.3 Region的性质
结合region的定义,不难得到以下性质:
- region的entry支配其余所有节点。但不一定支配exit。
- region的exit后支配region所有节点。
3. RegionTree的构建
LLVM的RegionPass按照由内到外的顺序处理region,最外层的region最后处理。因此,LLVM需要识别出函数中的region,并将region之间的层次关系表示出后才能进行region分析。那么,最自然的方式就是构建函数的RegionTree。
我们令RegionTree中的节点表示一个region,边表示region之间的包含关系。通过对树进行逆先序遍历就能保证,一个region的所有subregions都先于该region被分析。事实上,LLVM中的RGPassManager就是按照RegionTree的逆先序遍历方式逐一处理region的。
3.1 RegionInfo Pass
LLVM使用RegionInfoPass实现RegionTree的构建。该pass是一个FunctionPass,需要用到节点的支配者、后支配者以及支配边界,因此该pass首先会获取函数的支配树、后支配树与支配边界,然后调用recalculate函数进行计算。相关代码如下:
bool RegionInfoPass::runOnFunction(Function &F) {
releaseMemory(); // 释放RegionInfo 占有的一些动态分配内存
auto DT = &getAnalysis<DominatorTreeWrapperPass>().getDomTree();
auto PDT = &getAnalysis<PostDominatorTreeWrapperPass>().getPostDomTree();
auto DF = &getAnalysis<DominanceFrontierWrapperPass>().getDominanceFrontier();
RI.recalculate(F, DT, PDT, DF); // 重新计算
return false;
}
recalculate函数首先创建顶级region(TopLevelRegion),并以它作为RegionTree的根。所谓顶级region,其实就是整个函数,它的entry就是函数的entry,它的exit则为空。我们可以认为函数有一个虚拟的exit,所有退出基本块(return, unreachable, abort等)都连向该虚拟exit,故而表示顶级region的exit是空的。在图1中,蓝色区域就是顶级region。创建完顶级regioin之后,recalculate会调用calculate来构建RegionTree。
calculate分两个阶段进行:
- 第一阶段会找出函数中的所有region。
- 第二阶段则将发现的regions组织成树。
两阶段分别由函数scanForRegions、buildRegionsTree实现。
3.2 寻找CFG中的所有Region
scanForRegions找region的方式暴力直接。按照支配树的后序遍历处理每个节点,对每个节点,调用findRegionsWithEntry找出所有以它为entry的regions。
template <class Tr>void RegionInfoBase<Tr>::scanForRegions(FuncT &F, BBtoBBMap *ShortCut) {
using FuncPtrT = std::add_pointer_t<FuncT>;
BlockT *entry = GraphTraits<FuncPtrT>::getEntryNode(&F);
DomTreeNodeT *N = DT->getNode(entry);
// Iterate over the dominance tree in post order to start with the small regions from the bottom of the dominance tree. If the small regions are
// detected first, detection of bigger regions is faster, as we can jump over the small regions.
for (auto DomNode : post_order(N))
findRegionsWithEntry(DomNode->getBlock(), ShortCut);
}
findRegionsWithEntry接收两个参数,第一个参数是作为entry的基本块,第二个则是辅助数据结构ShortCut,它记录每个基本块作为起始,所能形成的最大region。该函数查找region的逻辑如下:
- 沿着后支配树遍历entry的所有后支配点exit。
- 判断(entry, exit)是否是一个合法的region。
- 如果合法,并且不是trival的,则将其插入BBToRegion中。同时,如果前面的迭代中已经发现了某个region,则将其设为当前region的子region。
相关代码如下:
template <class Tr>
void RegionInfoBase<Tr>::findRegionsWithEntry(BlockT *entry,
BBtoBBMap *ShortCut) {
DomTreeNodeT *N = PDT->getNode(entry); // entry所在后支配树中的节点
if (!N) return;
RegionT *lastRegion = nullptr; // 记录最近一次形成的region
BlockT *lastExit = entry; // 最近一次尝试的exit节点
while ((N = getNextPostDom(N, ShortCut))) { // 遍历后支配点
BlockT *exit = N->getBlock();
if (!exit) break; // 遍历完后支配树,退出
if (isRegion(entry, exit)) { // 判断是否是一个region,若是,则记录该region,并更新subregion
RegionT *newRegion = createRegion(entry, exit);
if (lastRegion)
newRegion->addSubRegion(lastRegion);
lastRegion = newRegion;
lastExit = exit;
}
if (!DT->dominates(entry, exit)) // entry如果不支配exit的话,无需形成更大范围的region,提前退出
break;
}
if (lastExit != entry)
insertShortCut(entry, lastExit, ShortCut); // 更新shortcut
}
使用getNextPostDom查找下一个后支配点时,会先判断N所表示的基本块是否在shortcut中,如果在,则返回postdom(ShortCut[N->getBlock),否则返回postdom(N->getBlock)。下图展示了这两种情形:
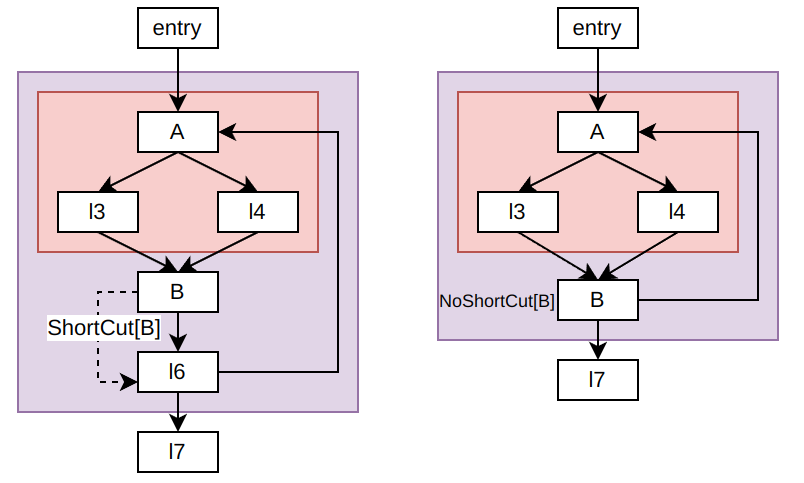
假设findRegionsWithEntry的entry参数是A,则第一次调用getNextPostDom会输入A返回B。第二次调用getNextPostDom会输入B,左图会返回postdom(ShortCut[B]),也就是l7;右图则因为不存在ShortCut[B](B无法形成region),返回postdom(B),同样是l7。
引入ShortCut可以跳过位于其他region的基本块,加速region的查找;同时也能避免形成部分相交的region,保证找到的region之间只有包含关系。
那么当我们找到了一个候选的region (entry, exit)后,怎么判断该region是一个合法的region呢?可以分两种情形进行讨论:
- 当entry不支配exit时,如果entry的支配边界只包含自己或者exit,则该region是一个合法的region,否则非法。
- 当entry支配exit时,如果该region含有非法的入边(入边不指向entry),或者含有非法的出边(出边不指向exit),则该region非法,排除这两种情形就是合法的region。
- 判断非法入边的方式为:遍历exit的支配边界,如果某个支配边界被entry严格支配,且不为exit(排除exit到自己的循环),那么就找到了一条非法入边;
- 判断非法出边的方式为:遍历entry的支配边界,如果存在某个支配边界不是exit的支配边界,就找到了一条非法出边。
- 下图展示了存在非法入边与非法出边的例子:
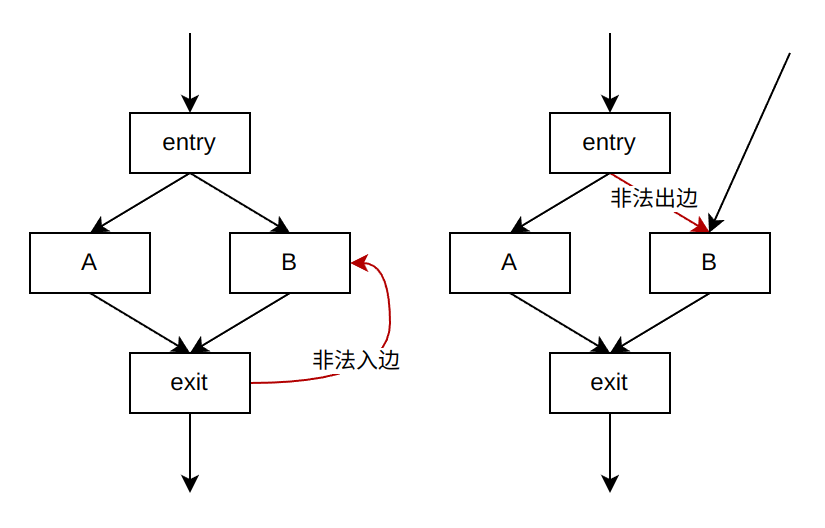
llvm中判断region的逻辑由isRegion实现,基本思路同上。读者可以对照着阅读源码。至此,我们已经讲解了寻找函数所有region的算法,下面将讲解如何将这些region组织成树。
3.3 将Region组织成树
在scanForRegions中,所有非trival的region都被保存在BBToRegion中。给定一个基本块BB,可以通过BBToRegion查询以它作为entry的最内层region。此外,含有相同entry的region也已经建立起了父子关系。但是目前还没有建立完整的RegionTree,同时对于region的非entry节点也还没确定其所在的region。因此buildRegionsTree需要解决这两个问题。
LLVM通过对支配树进行一次DFS遍历完成RegionTree的构建,同时将非entry节点所属的region记录到BBToRegion中。DFS函数的输入参数为当前要处理的节点N,以及一个Region R。这两个参数在DFS过程中维持了以下不变量关系:
- N是R的exit。
- N不是R的exit,并且不存在以N为entry的region,则R是N所在的region。
- N不是R的exit,并且存在以N为entry的region。那么令X是以N为entry的最外层region,则R是X的父region。
对于情形1,不断更新R为R的父region,直至N不再是R的exit,此后的操作按照情形2或3处理;对于情形2,设置BBToRegion[N] = R;对于情形3,将X的父region设为R。
处理完后,继续DFS 支配树中N的子节点。LLVM中,DFS函数buildRegionsTree的实现及注释如下:
template <class Tr>
void RegionInfoBase<Tr>::buildRegionsTree(DomTreeNodeT *N, RegionT *region) {
BlockT *BB = N->getBlock();
// case 1:不断更新region为其父region,直至region的exit不再是BB。
while (BB == region->getExit())
region = region->getParent();
typename BBtoRegionMap::iterator it = BBtoRegion.find(BB);
// This basic block is a start block of a region. It is already in the
// BBtoRegion relation. Only the child basic blocks have to be updated.
if (it != BBtoRegion.end()) { // case 3: 将以BB为entry的最外层region的父region设置为regioin。
RegionT *newRegion = it->second;
region->addSubRegion(getTopMostParent(newRegion));
region = newRegion;
} else { // case 2: 将非entry基本块所在的region记录到BBtoRegion中
BBtoRegion[BB] = region;
}
for (DomTreeNodeBase<BlockT> *C : *N) { // 继续DFS N的子节点
buildRegionsTree(C, region);
}
}
buildRegionsTree的起始参数是函数的entry基本块与TopLevelRegion。执行完后将得到完整的RegionTree(根为TopLevelRegion)。同时,所有基本块所属的最内层region保存在BBtoRegion中。
4. Region的使用
与region关系紧密的类有RegionNode,Region以及RegionInfo 3个。
- RegionNode代表region内的某个节点,要么是一个单独的基本块,要么是一个subregion。
- Region则专指非单个基本块的region。
- RegionInfo负责region的挖掘以及RegionTree的构建,并保存结果。
下面介绍这三个类的基本功能,具体API的使用可配合源代码的注释自行阅读。
4.1 RegionNode
A RegionNode represents a subregion or a BasicBlock that is part of a Region.
我们考虑一个region中的基本块,这些基本块要么属于某个subregion,要么直接归属该region。那么可以将直属于regioin的subregioin以及基本块抽象成一个节点。这就是RegionNode的设计理念。不难想到描述一个RegionNode需要以下信息:
- entry基本块:如果RegionNode是单个基本块,那么该基本块就是entry;如果是subregion,则为其entry基本块。
- isSubRegion标志:区分node的类型。
- node所属的父region:一般表示该node的直接父region,但也可以表示其某个祖先region。具体需要看node构造时的参数。
注意到RegionNode可能代表普通基本块,因此该类不描述region的exit节点信息。如果需要遍历RegionNode的后继,可以使用RNSuccIterator迭代器,它有两种特化,对应两种后继的遍历方式:
- RNSuccIterator<RegionNode, BasicBlock, Region>:如果当前node是基本块,则遍历基本块的后继,并跳过region exit;否则,该node是subregion,直接遍历其唯一exit,如果该exit恰好是region的exit,则同样跳过。
- RNSuccIterator<FlatIt
, BasicBlock, Region>:该迭代器将subregion拍平,因此无论node是否是基本块,都按照基本块的后继遍历,并跳过region exit节点。
4.2 Region
Region继承了RegionNode类,因此自然包含了RegionNode的描述信息。但同时,也扩充了以下信息:
- exit基本块:表示region的退出基本块。
- 该region包含的subregions,用成员children记录。
- 某些api需要的辅助数据成员。如RegionInfo、DomTree、BBNodeMap(记录非subregion基本块对应的RegionNode)
Region相关的API函数比较简单,可自行查阅头文件中的注释说明。这里说明一下几个容易混淆的函数以及Region内的迭代器。
- getNode函数
- getNode()函数将Region强制转换成基类RegionNode。
- getNode(BasicBlock *BB)根据BB类型返回RegionNode。如果BB是subregion的entry基本块,则返回代表该subregion的RegionNode;否则返回代表单个基本块的RegionNode。不管如何,返回的RegionNode的parent都设置为当前region。
- getBBNode(BasicBlock *BB)返回单个BB基本块表示的RegionNode。
- begin()/end()
- 遍历subregions。
- block_begin()/block_end()
- dfs遍历region内的所有基本块。
- element_begin()/element_end()
- dfs遍历region的直接subregion与block对应的RegionNode。
4.3 RegionInfo
RegionInfo主要用途就是实现Region的挖掘与RegionTree的构建,在之前的章节中已经讲解了这两个过程。分析的结果最终保存在两个数据结构中:
Region *TopLevelRegion
保存RegionTree的根节点,可通过它遍历整个树。
BBtoRegionMap BBtoRegion
将每个基本块映射到最小的包含它的region。